ОБЗОР МЕТОДОВ КЛАССИФИКАЦИИ ТРАФИКА
Журнал: Научный журнал «Студенческий форум» выпуск №21(200)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №21(200)
ОБЗОР МЕТОДОВ КЛАССИФИКАЦИИ ТРАФИКА
Введение
Сетевой трафик постоянно развивается и изменяется в связи с чем и методы классификации трафика должны постоянно модифицироваться, чтобы соответствовать новым требованиям и ограничениям. С изменением устройства сетевого трафика старые методы классификации становятся неэффективны или вовсе непригодны. Так же развитие средств классификации трафика позволяет детальнее разделять потока благодаря чему находится больше способов применения классификации.
Основными характеристиками методов классификации интернет трафика являются:
- детализация: определяет насколько глубоко производится классификация. Определяется семейство протоколов, класс приложений, конкретный протокол или конкретное приложение;
- скорость реакции: насколько быстро метод способен производить классификацию. Определяется количеством пакетов потока необходимое для определения трафика, возможностью работы в реальном времени и скоростью обработки пакетов;
- вычислительная стоимость: ресурсы необходимые для проведения классификации. Определяется сложностью вычислений, требуемых для обработки одного потока или пакета, а также объёмом памяти необходимым для классификации.
Для разных целей могут быть использованы классификаторы, достигающие разной детализации при классификации пакетов. Более высокий уровень детализации зачастую достигается более высокими требованиями к вычислительной стоимости, а также требует больший объём информации о потоке, что приводит к снижению скорости реакции. В связи с чем зачастую при выборе метода классификации трафика приходится принимать решение о том, что приоритетнее: скорость работы, вычислительная стоимость или глубина классификации.
Классификация по номерам портов
Первые методы классификации трафика были основаны на определении номеров портов пакетов. По номеру порта можно определить приложение или протокол, который использует этот номер в соответствии с списком IANA (Internet Assigned Numbers Authority). IANA регистрирует номера портов, которые используются для конкретных целей. К примеру, под протокол HTTP выделен восьмидесятый порт, а под протокол HTTPS четыреста сорок третий.
Классификация производится очень быстро, так как необходимо только получить значение определённых байт пакета, и не требует высоких вычислительных ресурсов, так как не требует хранить никакую информацию о пакете, или потоке трафика, к которому он принадлежит. Информацию об используемом протоколе можно использовать для определения типа деятельности пользователя, однако значение порта позволяет определить только протокол трафика, и не позволяет определить используемое приложение, так как очень многие приложения используют протокол HTTP или HTTPS.
Так как сеть быстро развивается, определение портов для всех протоколов и приложений становится невозможным. Многие протоколы остаются не зарегистрированными IANA, а также помимо этого некоторые порты могут использоваться несколькими классами трафика. Некоторые протоколы определяют порт для обмена данными в процессе работы, что делает классификацию трафика, основанную на извлечении номера порта полностью бесполезной.
Помимо этого, некоторые протоколы могут специально использовать известные номера портов других протоколов, чтобы замаскироваться под них, и таким образом избежать блокировок. Например, протокол BitTorrent может использовать восьмидесятый порт, чтобы маскироваться под протокол HTTP, и таким образом обходить блокировки и ограничение скорости передачи трафика.
Таким образом в настоящее время этот метод не может однозначно определить класс трафика, и может быть использован только как один из признаков, используемых при принятии решения о принадлежности пакета тому или иному классу трафика.
Глубокий анализ пакетов
С развитием трафика оказалось, что для определения класса трафика недостаточно данных, которые можно получить из заголовков пакетов, что привело к необходимости использовать полное содержимое пакетов трафика, для их классификации.
Глубокий анализ пакетов - это совокупное название технологии, позволяющей проводить в режиме реального времени накопление, анализ, классификацию, контроль и модификацию сетевых пакетов в зависимости от их содержимого [1].
Основа работы данного метода заключается в проверке содержимого пакетов при помощи сигнатур – шаблонов описания данных соответствующих определённому протоколу или приложения. Зачастую производится поиск ключевых слов в конкретных частях пакета. Точность работы этого метода очень высока, и пакеты, размеченные с помощью методов глубокого анализа пакетов, зачастую используются как эталонные.
Однако в связи с тем, что данный метод предполагает сопоставление большого объёма данных пакетов с библиотекой сигнатур, вычислительные затраты становятся очень высокими, а скорость реакции низкой. При высокой скорости роста количества классов трафика, растёт и объём библиотеки сигнатур, на хранение которой требуется большое количество места. В связи с этим данный метод не подходит для использования в высокоскоростных сетях в режиме реального времени, так как требует слишком больших вычислительных ресурсов, для того чтобы справиться с нагрузкой.
Ещё одной проблемой при использовании содержимого пакетов становится то, что за последнее время существенно выросла доля зашифрованного трафика, который не может быть классифицирован этим методом.
Так же поднимается вопрос защиты личной информации пользователей сети, так как в данном методе используется полезная нагрузка пакетов трафика. Это вынуждает учитывает законодательную сторону этого аспекта и применять методы, работающие с ограниченным объёмом данных. К примеру, в работе [2], было принято решение использовать первые 40 битов данных.
Анализ статистических характеристик пакетов
Для снижения вычислительных затрат и повышения скорости работы классификации были разработаны методы использующие статистические характеристики пакетов и потоков трафика, для принятия решения о принадлежности трафика тому или иному классу. Классификаторы, относимые к данному классу, могут применять существенно отличающиеся друг от друга методы: поиск статистических сигнатур, по которым можно отличить приложения друг от друга, интенсивность поступающих пакетов, среднее значение и дисперсия размеров пакетов [3].
В работе [4] представлен метод оптимизации процесса извлечения заголовков уровня приложения при помощи критерия Хи-квадрат Пирсона. Изучается распределение первых байтов полезной нагрузки пакета и выделяет из них требуемые для классификации сигнатуры, которые в дальнейшем используются для классификации используемого приложения.
Данный метод классификации подходит для работы с зашифрованным трафиком так как может работать, используя только заголовки пакетов и статистическую информацию о них. Также в работе [5] показано, что, используя статистические методы можно выявить является ли трафик зашифрованным. Вычисляется энтропия полезной нагрузки первого пакета каждого потока, и на основе её значения делается вывод о том, является ли трафик зашифрованным или нет.
Методы классификации, принадлежащие этому классу, требуют меньшего объёма памяти чем методы глубокого анализа пакетов, но зачастую требуют большей вычислительной мощности, так как не просто сравнивают содержимое пакетов с шаблонами, а вычисляют признаки, которые используются для классификации. Так же недостатком является то, что эти методы зачастую могут только выделить признаки, на основе которых будет производиться дальнейшая классификация трафика, и не могут самостоятельно принять решение о классе исследуемого пакета.
Классификация трафика методами машинного обучения
В отличие от методов классификации по номерам портов и глубокого анализа пакетов данный класс методов классификации трафика имеет широкий диапазон решений, как для узконаправленных, так и для широких задач. Существует большое множество методов машинного обучения, которые используются для классификации интернет трафика. Среди методов можно выделить:
- наивный байесовский классификатор;
- метод опорных векторов;
- деревья принятия решений;
- случайный лес;
- нейронные сети.
Широкое разнообразие методов позволяет варьировать вычислительные и временные потребности классификации, и настраивать классификацию под решение конкретных узких задач. Методы машинного обучения могут работать не только с полезной нагрузкой, но и с общими признаками пакетов и потоков трафика, благодаря чему можно ускорить классификацию и избежать проблем с нарушением конфиденциальности пользователей.
Классификация трафика с использованием методов машинного обучения, обычно рассматривается как задача обучения с учителем, где подготавливаются пакеты трафика, заранее разделённые на классы. От качества подготовленных пакетов зависит точность определения обученной моделью класса при тестировании, и работе.
Однако, так как для обучения классификатора требуются только размеченные пакеты трафика, существенно снижается человеческое вмешательство в процесс обучения и настройки классификатора. Для обучения классификаторов основанный на методах машинного обучения не требуется привлечение экспертов, и некоторые методы позволяют производить автоматическую перенастройку, не прекращая работу, и не требуя вмешательства администратора.
Наивный байесовский классификатор
Наивный байесовский классификатор – простой вероятностный классификатор, работа которого основана на применении Теоремы Байеса со строгими предположениями о независимости признаков [6].
Для принятия решения о классе изучаемого объекта вычисляется его условная вероятность, по формуле:
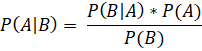
где  – Вероятность класса A при условии, что признак B истина;
– Вероятность класса A при условии, что признак B истина;
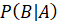 – вероятность возникновения признака B в классе A;
– вероятность возникновения признака B в классе A;
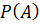 – вероятность появления класса A;
– вероятность появления класса A;
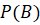 – вероятность возникновения признака B (вычисляется в процессе обучения).
– вероятность возникновения признака B (вычисляется в процессе обучения).
Данный вид классификатора является одним из наиболее простых методов машинного обучения, благодаря чему обладает высокой скоростью обучения и работы. Но из-за наивного предположения о независимости признаков, зачастую работает хуже других методов машинного обучения. В работе [7] представлено сравнение методов машинного обучения, и показано что наивный байесовский классификатор уступает в точности прогнозирования.
Метод опорных векторов
Метод опорный векторов заключается в представлении каждого исследуемого экземпляра в виде вектора в p-мерном пространстве, и поиска гиперплоскости размерности p-1, разделяющей точки относящиеся к разным классам с наибольшим зазором. Таким образом можно производить бинарную классификацию. Для решения задачи многоклассовой классификации можно обучать N классификаторов, каждый из которых будет учиться отличать свой класс, где N число исследуемых классов.
Преимуществом данного метода является его эффективность в многомерных пространствах признаков, но данный метод очень затратен по памяти и вычислительных ресурсах, в особенности при проведении многоклассовой классификации, а также обладает проблемой переобучения, когда классификатор обучается корректно определять только объекты на которых производилось обучение, в связи с чем он редко используется для решения задачи классификации трафика.
Деревья принятия решений
Классификация методом дерева принятия решений представляет собой спуск по бинарному дереву, в вершинах которого записаны признаки, по которым производится классификация, на рёбрах значения этих признаков, а в листьях результат классификации. Из полученного пакета трафика выделяются признаки необходимые для классификации, и на основе значений этих признаков производится спуск по дереву. Результатом классификации будет класс, указанный в листе дерева к которому приведут значения признаков.
Бинарные деревья различаются по наборам признаков, используемых для классификации и по алгоритмам их построения. В работе [8] представлен алгоритм построения дерева решений C4.5 демонстрирующий очень высокую точность классификации. Помимо этого, в работе сравнивалась вычислительная сложность алгоритмов, и эксперименты показали, что данный алгоритм имеет наименьшую сложность при тестировании. Алгоритм С4.5 позволяет задавать веса для признаков, может использовать как дискретные, так и непрерывные признаки, и производит прореживание построенных деревьев с целью их оптимизации.
В работе [9] представлено сравнение методов С4.0 и С5.0. Алгоритм С5.0 является оптимизированной версией алгоритма С4.0, дающей преимущество в скорости работы и используемой памяти засчёт построения деревьев меньшего размера, не теряя при этом точности классификации.
Классификаторы основанные на деревьях принятия решений позволяют классифицировать трафик с очень высокой точностью, требуя меньше данных для проведения анализа. Так же данный метод легко настраивается для проведения мультиклассовой классификации. Однако, так же обладают и недостатками в виде риска переобучения, неустойчивости к небольшим изменениям входных данных и не оптимальности алгоритмов построения дерева.
Случайный лес
Алгоритм случайного леса является композицией из набора деревьев принятия решений. Благодаря объединению группы простых алгоритмов повышается стабильность и точность работы системы. Основная идея в использовании большой группы деревьев принятия решений, каждое из которых само по себе выполняет классификацию с очень невысокой точностью, но благодаря большому количеству деревьев итоговое решение получается высокой точности.
Классификация производится на основе решений каждого из деревьев о принадлежности объекта классу. Класс объекта определяется исходя из того, какой класс приняло большинство деревьев. Так же деревья могут иметь веса, которые будут учитываться при сравнении результатов классификации деревьев.
Данный метод обладает очень высокой точностью классификации и стабильностью работы, но требует больше вычислительных ресурсов чем метод основанный на одном дереве принятия решений. В работе [10] показано, что данный метод может применяться для классификации зашифрованного трафика, и в сравнении с остальными методами он показал наибольшую точность, но ценой наименьшей скорости работы. Так же модели, построенные этим методом гораздо сложнее и не позволяют находить в них определённые закономерности.
Нейронные сети
Искусственные нейронные сети состоят из нескольких слоёв нейронов, каждый из которых выдаёт определённую ответную реакцию на входные сигналы. Каждый слой сети состоит из определённого, заранее заданного числа нейронов, каждый из которых может быть соединён с любыми нейронами из предыдущего или последующего слоёв.
Модели нейронных сетей различаются по типам связей (полносвязная, свёрточная, и прочие), а также по направлению распространения сигнала (прямого распространения или рекурентные). Наиболее распространёнными являются сети прямого распространения, в которых сигнал передаётся последовательно от слоя к слою и не возвращает никакого отклика обратно на вход. В рекурентных нейронных сетях сигнал частично передаётся обратно на вход нейронной сети, с целью сохранения информации об изученном пакете.
Нейронные сети обучаются с учителем, и для корректировки весов своих нейронов используют метод обратного распространения ошибки. В зависимости от полученного выходного значения нейронной сети и ожидаемого выхода определяется ошибка классификации сети, и эта ошибка передаётся с выходного слоя обратно на входной корректируя веса нейронов.
Для работы с большим количеством признаков часто применяются свёрточные нейронные сети. Нейронные сети данного типа учатся находить закономерности в обучающей выборке, и на основе них принимать решение о принадлежности, или не принадлежности трафика к исследуемому классу. Благодаря тому, что сеть не является полносвязной достигается высокая скорость работы.
Рекуррентные нейронные сети позволяют производить классификацию объектов, меняющихся во времени, благодаря чему можно классифицировать поток трафика передавая на вход нейросети последовательно идущие пакеты. Данные об уже исследованных пакетах накапливаются благодаря чему повышается и точность классификации.
Автокодировщик – полносвязная нейронная сеть состаящая из двух частей: кодировщика, и декодера. В начале входящая последовательность сжимается, а затем восстанавливается обратно. В процессе обучения автокодировщик учится корректно восстанавливать входную информацию, и так как точно воссоздавать он может только информацию того типа, на котором производилось обучение, можно судить о принадлежности исследуемого пакета данному классу по точности воспроизведения его данных.
Выводы
В работе были рассмотрены основные методы классификации трафика. Рассмотрены их сильные стороны и недостатки, а также принципы на которых основана их работа.
Исходя из изученной информации наиболее перспективны классификаторы, основанные на алгоритмах машинного обучения, обладающие высокой скоростью работы и наивысшей точностью классификации из всех рассмотренных методов.
