Статья:




РЕАЛИЗАЦИЯ ПРОЦЕССА KDD В DEDUCTOR STUDIO НА ПРИМЕРЕ АНАЛИЗА РЫНКА СТРАХОВАНИЯ
Секция: 3. Информационные технологии
Выходные данные
Коновалова Е.К. РЕАЛИЗАЦИЯ ПРОЦЕССА KDD В DEDUCTOR STUDIO НА ПРИМЕРЕ АНАЛИЗА РЫНКА СТРАХОВАНИЯ // Молодежный научный форум: Технические и математические науки: электр. сб. ст. по мат. XIX междунар. студ. науч.-практ. конф. № 12(19). URL: https://nauchforum.ru/archive/MNF_tech/12(19).pdf (дата обращения: 03.08.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 0 голосов
Мне нравится0
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

XIX Студенческая международная заочная научно-практическая конференция «Молодежный научный форум: технические и математические науки»
РЕАЛИЗАЦИЯ ПРОЦЕССА KDD В DEDUCTOR STUDIO НА ПРИМЕРЕ АНАЛИЗА РЫНКА СТРАХОВАНИЯ
Коновалова Екатерина Константиновна
студент НИУ «ВШЭ-Пермь», РФ, г. Пермь
Дерябин Александр Иванович
научный руководитель, канд. техн. наук, доц. НИУ «ВШЭ-Пермь», РФ, г. Пермь
В современном мире каждая организация стремится повысить прибыль и уменьшить расходы, построить процесс своей деятельности максимально эффективно и научиться уверенно смотреть вперед. Новые компьютерные технологии, программы автоматизации бизнес-процессов, совершенствуясь с каждым годом, позволяют избежать или предугадать ситуацию в настоящем и будущем.
Чем внимательнее и точнее ведется составление и систематизация информации, тем адекватнее будет представление о процессах в организации. В наше время носители позволяют хранить невероятное количество информации, однако без применения специальных средств анализа такие носители превращаются в бесполезную свалку данных. Отнюдь не редки случаи, когда принятие правильного управленческого решения затруднено отсутствием упорядоченности: данные являются неполными или избыточными, замусорены информацией, которая не имеет отношения определенной области, неструктурированными или систематизированными неверно. В такие моменты особенно остро проявляется необходимость в программных средствах, которые позволят привести информацию к необходимому виду, достоверно оценить содержащиеся в ней факты и повысить вероятность принятия оптимального решения.
Один из вариантов использования программного обеспечения для анализа — это построение моделей. Модель имеет возможность имитировать любой процесс. Чтобы построить надежную модель, требуется сделать предобработку данных для дальнейшего применения математических методов анализа. Полученная модель может быть использована для принятия решений, для оценки значимости факторов, для моделирования различных вариантов развития.
KDD (Knowledge Discovery in Databases) — это процесс поиска полезных знаний в «сырых данных» или извлечение их из баз данных.
Основное преимущество этого подхода заключается в том, что он универсален для любой области. Необходимо последовательно выполнить пять шагов, чтобы получить качественный результат:
1. Подготовка исходного набора данных. На данном этапе собираются данные из различных источников, формируется общий набор данных, а потом задается конкретная выборка, которая впоследствии должна анализироваться.
Рынок страховых услуг принято делить на два больших сегмента:
· Обязательное страхование.
Входит в обязанности физических и юридических лиц в соответствии с законодательством РФ.
· Добровольное страхование.
Дополняет обязательное страхование, расширяет возможности страховой защиты.
Действующим гражданским кодексом Российской Федерации предусмотрены следующие виды страхования:
· Имущественное страхование.
Договор страхования имущества предусматривает возмещение страхователю материального ущерба застрахованного имущества в размере, прописанном в данном договоре, в случае наступления страхового события. Объектом страхования может выступать движимое и недвижимое имущество.
· Личное страхование.
При заключении договоров личного страхования страховым объектом является жизнь или здоровье (от несчастных случаев; медицинское, пенсионное страхование и т. д.). Страховое возмещение выплачивается страховому лицу при наступлении болезни или несчастного случая.
· Страхование ответственности.
В качестве объекта страхования по данному виду является гражданская ответственность и ответственность перед третьими лицами при различных видах страховых рисков. Страховые выплаты осуществляются участником страхового события в соответствии с условиями и порядком выплат, прописанных в договоре.
· Перестрахование.
Подразумевает под собой передачу части финансовых рисков от одного страховщика другому страховщику. Это делается для повышения финансовой устойчивости участников страхового рынка. Чаще всего договоры перестрахования заключаются с крупными страховщиками на рынке страховых услуг.
Далее необходимо опередить способ представления данных (число, строка, дата, логическая переменная). Формализовать данные довольно просто: объем страховых выплат в рублях — это определенное число.
Для рынка страхования было использовано несколько файлов Excel с таблицами по разным видам страхования и регионам. Эти таблицы были проанализированы, выделены общие данные, заполнены пробелы, трансформированы таблицы со сложными классификациями. (Рисунок 1.), (Рисунок 2.)

Рисунок 1. Сведения о выплатах и премиях по видам страхования
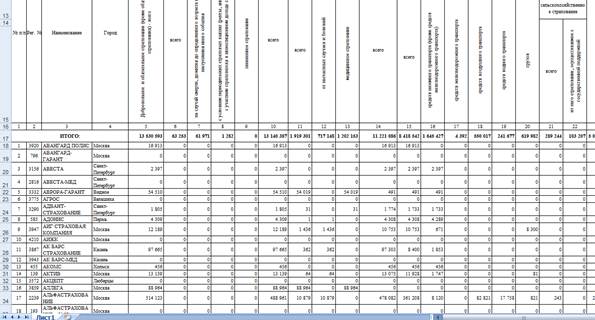
Рисунок 2. Сведения о выплатах по договорам перестрахования по регионам
Итоговая таблица с приведенными данными была скопирована в файл *txt для дальнейшего импорта в Deductor. (Рисунок 3.)

Рисунок 3. Текстовый файл для дальнейшего импорта
2. Предобработка и очистка данных. Для того чтобы эффективно применять методы анализа, следует обратить серьезное внимание на вопросы предобработки данных.
Очевидно, что исходные данные нуждаются в очистке. Проблемы, разрешаемые на этапе очистке данных: аномалии, пропуски, шумы и прочие.
Один из методов очистки данных — парциальная обработка.
В процессе парциальной обработки восстанавливаются пропущенные данные, редактируются аномальные значения, устраняются шумы. (Рисунок 4.)

Рисунок 4. Мастер обработки. Парциальная обработка.
На первом этапе очистки редактируем аномалии. Для применения алгоритма удаления аномалий необходимо указать элемент таблицы, к которому нужно применить и выбрать один из пунктов в строке степени подавления аномальных данных. (Рисунок 5.)
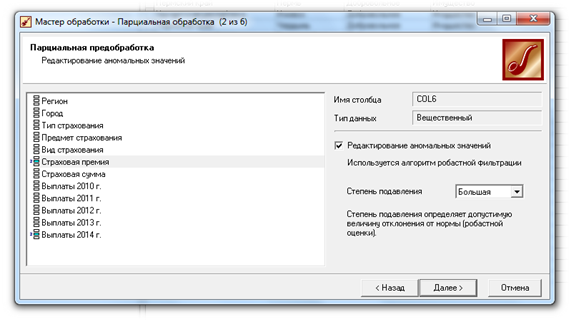
Рисунок 5. Редактирование аномальных значений
Таким образом, после избавления от аномалий получается следующая диаграмма: (Рисунок 6.)

Рисунок 6. Диаграмма данных после удаления аномалий
Далее производится очистка от шумов. Шумы портят обобщающие качества модели. При выборе режима очистки от шумов необходимо выбрать степень вычитания шума. В нашем случае, рассмотрена малая степень вычитания шума. Диаграмма данных выглядит соответственно: (Рисунок 7.)

Рисунок 7. Диаграмма данных после очистки от шумов
3. Трансформация данных. Для различных методов анализа требуются данные, подготовленные в специальном виде.
Для рынка страхования был использован метод «Скользящее окно». Суть этого метода заключается в следующем: значения в одной из ячеек записи будут относиться к отсчету в настоящем времени, а в других полях будут смещены от этого отсчета «в будущее» или «в прошлое». Получается, преобразование скользящего окна имеет два параметра: «глубина погружения» — количество отсчетов за прошедшие периоды и «горизонт прогнозирования» — количество отсчетов в будущие периоды.
На данном примере можно проверять страховые выплаты в разные промежутки времени и при необходимости заполнить пропущены данные. (Рисунок 8), (Рисунок 9).
Рисунок 8. Скользящее окно

Рисунок 9. Диаграмма скользящего окна
4. Data Mining (DM) — «добыча» данных. Это метод нахождения в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных для интерпретации знаний, которые необходимы для принятия решений в различных сферах жизни.
На данном этапе применяются всевозможные алгоритмы для поиска знаний: нейронные сети, деревья решений, алгоритмы кластеризации и установления ассоциаций. Здесь можно наблюдать распространенные статистические методы, самообучающиеся алгоритмы и машинное обучение.

Рисунок 10. Нейросеть 3 слоя
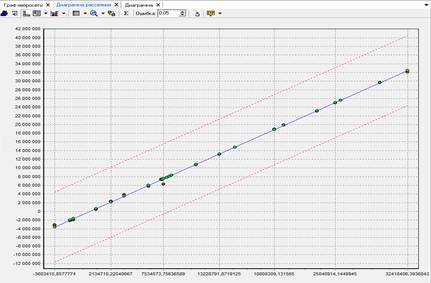
Рисунок 11. Диаграмма рассеяния
5. Постобработка данных. Оценка результатов, тестирование модели.
Для оценки качества моделей прогноза можно вновь обратиться к диаграмме рассеяния. На этой диаграмме отображается отклонение истинного значения от прогнозного.
Резкие отклонения величины говорит о плохо построенной модели и необходимости увеличения преобразований над данными. В нашем случае значительных отклонений не замечено. Следовательно, модель построена корректно.
Список литературы:
1. Палкин Н.Б., Орешков В.И. Бизнес-аналитика: от данных к знаниям. Санкт-Петербург: Питер, 2010.
2. Deductor. Руководство аналитика — [Электронный ресурс] — Режим доступа. — URL: http://www.basegroup.ru/download/guide_analyst_5.2.0.pdf (дата обращения 01.09.2012).
