Статья:




Выбор длины кадра при кратковременном анализе речевого сигнала
Секция: Технические науки
Выходные данные
Чан Ч.Х., Миноваров Т.Р. Выбор длины кадра при кратковременном анализе речевого сигнала // Молодежный научный форум: Технические и математические науки: электр. сб. ст. по мат. XLI междунар. студ. науч.-практ. конф. № 1(41). URL: https://nauchforum.ru/archive/MNF_tech/1(41).pdf (дата обращения: 01.08.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 45 голосов
Мне нравится45
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

XLI Студенческая международная заочная научно-практическая конференция «Молодежный научный форум: технические и математические науки»
Выбор длины кадра при кратковременном анализе речевого сигнала
Чан Чунг Хиеу
студент, Белгородский государственный национальный исследовательский университет, РФ, г. Белгород
Миноваров Тимур Ренатович
студент, Белгородский государственный национальный исследовательский университет, РФ, г. Белгород
Прохоренко Екатерина Ивановна
научный руководитель, канд. техн. наук, доц., Белгородский государственный национальный исследовательский университет, РФ, г. Белгород
Научные исследования в области обработки речи ведутся почти столетие. Тенденции конвергенции технологий в XXI веке дают все большую мотивацию дальнейшему совершенствованию методов и алгоритмов в этой области.
Речь–это средство обмена информацией у людей. Звуки речи генерируются речевым аппаратом – совокупностью органов человека, необходимых для производства речи (рис. 1) [4].

Рисунок 1. Речевой аппарат. 1 – Твердое небо; 2 – Альвеолы; 3 – Верхняя губа; 4 – Верхние зубы; 5 – Нижняя губа; 6 – Нижние зубы; 7 – Передняя часть языка; 8 – Средняя часть языка; 9 – Задняя часть языка; 10 – Корень языка; 11 – Голосовые связки; 12 – Мягкое небо; 13 – Язычок; 14 – Гортань; 15 – Трахея
В целом звуки речи подразделяются на шумы и тоны: тоныв речи возникают в результате колебания голосовых связок;шумыобразуются в результате непериодических колебаний выходящей из лёгких струи воздуха. Тонами являются обычно гласные; почти же все глухие согласные относятся к шумам. Звонкие согласные образуются путём слияния шумов и тонов. Шумы и тоны исследуются по их высоте, тембру, силе и многим другим характеристикам. Наиболее известной характеристикой речевого сигнала являетсяосновной тон. Эта характеристика представляет собой обычную частотную модуляцию сигнала, параметры которой легко измеряются (установлено, что частота основного тона разных людей (мужчин, женщин, детей) находится в диапазоне 50–450Гц.). Классифицируется относительное изменение частоты, и траектория во времени при произнесении слова или фразы [2].
Кроме того, речь также обладает звуковыми свойствами. Классификация звуков может исходить как из акустических, так и артикуляционных признаков. При делении звуков на гласные и согласные и их внутренней классификации чаще всего учитываются те и другие признаки. Гласные – это звуки, при образовании которых в надгортанных полостях не встречается преград на пути воздушной струи: струя выдыхаемого воздуха свободно проходит через речевой канал. При характеристике гласных отмечают обычно и другие особенности: гласные – это тональные звуки. Для них характерно наличие музыкальных тонов (голоса), которые образуются работой голосовых связок. Согласные – это звуки, при образовании которых в надгортанных полостях или в гортани обязательно возникает та или иная преграда на пути воздушной струи (в виде сближенных или даже сомкнутых органов речи). Особенности акустической классификации состоят в том, что она описывает одним и тем же набором терминов гласные и согласные звуки. При этом акустическая классификация строится, как правило, на бинарном принципе, то есть двучленных противопоставлениях. Другими словами, применение бинарного принципа в акустической классификации при каждом членении дает два класса звуков речи [5].
Для автоматической классификации звуков речи используются классические методы частотного анализа, например преобразование Фурье, что предопределяет использование кратковременного анализа (Short-time-analysis), так как речевой сигнал является квази-стационарным на ограниченных временных промежутках, соответствующим отдельным звукам. Поэтому, при анализе речевого сигнала, он делится на равныевременные отрезки, которые называются кадрами (frame). Правильный выбор длины кадра является определяющим фактором в качестве последующего анализа [3].
В работе приведены некоторые исследования, позволяющие определить подход к выбору длины кадра при анализе речевых сигналов.
Минимальная длина кадра определяется периодом основного тона, то есть самой низкочастотной составляющей сигнала, и составляет примерно 20 мс. Максимальную длину кадра представляется правильным определять исход из длины квази-стационарных участков речевого сигнала, то есть участков, соответствующих отдельным звукам речи.
Для определения длительности звуков речи были записаны различные фразы, например повествовательное предложение «желаю, чтобы все», при этом намеренно делались паузы между словами и слогами для того, чтобы впоследствии было легче выделить на осциллограмме лексические элементы.
Далее определяласьдлительность каждого слова и звука (табл. 1, 2).
Таблица 1.
Определение длительности отдельных слов
|
Слово |
Длительность(мс) |
|
Желаю |
700 |
|
Чтобы |
570 |
|
Все |
384 |
Таблица 2.
Определение длительности отдельных звуков
|
Звук |
Ж |
е(1) |
л |
а |
Ю |
ч |
т |
|
Длительность (мс) |
117 |
94 |
55 |
76 |
350 |
144 |
73 |
|
Звук |
О |
б |
ы |
в |
С |
е(2) |
- |
|
Длительность (мс) |
150 |
57 |
97 |
93 |
95 |
200 |
- |
Средняя длительность звуков – 123 мс.
Из таблицы 2, видно, что длительность согласных букв «Ж, Л, Ч, Т, Б, В, С» составляет от 55 мс до 144 мс (средняя длительность – 90 мс). Длительность гласных букв «Е, А, О, Ю» –от 76 мс до 350 мс (средняя длительность – 174мс). Ударные звуки «Ю, О, Е(2)» имеют большую длительность, чем безударные (от 150 мс до 350 мс). Составные звуки« Е и Ю » длиннее простых «О».
Таким образом, максимальна длина кадра, для анализа звуков речи, может составлять не более 300 мс.
Для оценки соответствия звуков, выбранных автоматически, звукам выделенным «на слух», было проведено сравнение частотных спектров отрезков сигнала.
Например, выделялся отрезок речевого сигнала звука «А» и соответствующий ему кадр после автоматического разделениясигнала, при длительности кадров 38 мс, 76 мс и 152мс. Затем вычислялся коэффициент корреляции по формуле [1]:
 (1)
(1)
где: X – спектр сигнала, выбранного «на слух», Y – спектр сигнала, выбранного автоматически,  –средние значения сигналов.
–средние значения сигналов.
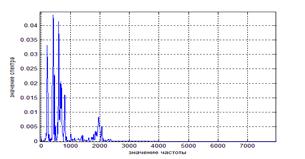
Рисунок 2. Спектр ручного выборного сигнала, длительность = 38 мс
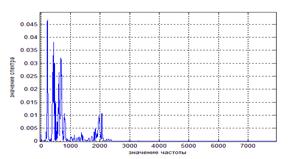
Рисунок 3. Спектр авто-выборного сигнала, длительность = 38 мс
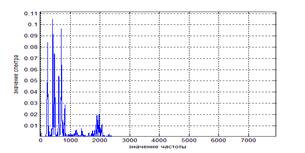
Рисунок 4. Спектр ручного выборного сигнала, длительность = 76 мс

Рисунок 5. Спектр авто-выборного сигнала, длительность = 76 мс

Рисунок 6. Спектр ручного выборного сигнала, длительность = 152 мс
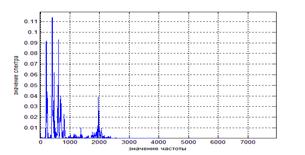
Рисунок 7. Спектр авто-выборного сигнала, длительность = 152 мс
Коэффициент корреляции при длительности 38 мс равен 0,9004, при длительности 76 мс – 0,8546, при длительности 152 мс – 0,7208.
Таким образом, чем меньше длительность кадра, тем больше коэффициент корреляции и тем более точен анализ речевых сигналов.
Список литературы:
1. Сергиенко А.Б., Цифровая обработка сигналов. [текст] / – СПб.: Питер, 2002. – 608 с.
2. Панов М.В., Энциклопедический словарь юного филолога (языкознание). [текст] / – М.: Педагогика, 1984. – С. 24–25.
3. Филичева Т.Б., Чевелева Н.А., Основы логопедии: Учеб. пособие для студентов пед. ин-тов по спец. «Педагогика и психология (дошк.)» [текст] / – М.: Просвещение, 1989. – 223 с.
4. Рабинер Л.Р., Шафер Р.В., Цифровая обработка речевых сигналов. Пер. с англ. [текст] / – М.: Радио и связь, 1981. – 496 с.
5. Исаков В.Н., Статистическая теория радиотехнических систем. [текст] / – М.: Радиотехника, 2003. – 400 с.
