Статья:




АВТОМАТИЗАЦИЯ ПРОЦЕССА ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
Секция: 3. Информационные технологии
Выходные данные
Попов А.В. АВТОМАТИЗАЦИЯ ПРОЦЕССА ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ // Молодежный научный форум: Технические и математические науки: электр. сб. ст. по мат. XVIII междунар. студ. науч.-практ. конф. № 11(18). URL: https://nauchforum.ru/archive/MNF_tech/11(18).pdf (дата обращения: 01.08.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 2 голоса
Мне нравится2
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

XVIII Студенческая международная заочная научно-практическая конференция «Молодежный научный форум: технические и математические науки»
АВТОМАТИЗАЦИЯ ПРОЦЕССА ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
Попов Александр Вячеславович
студент Поволжского Государственного Университета Телекоммуникаций и Информатики, РФ, г. Самара
Захарова Оксана Игоревна
научный руководитель, доц. Поволжского Государственного Университета Телекоммуникаций и Информатики, РФ, г. Самара
Традиционно любое предприятие ведет учет документации, персонала, данных о рабочей группе и т. д. Со времени появления первых компьютеров в сфере учета информации многое изменилось: появились электронные хранилища, вмещающие в себя объемы данных, сравнимые с целыми архивами; сам процесс ведения данных стал намного проще за счет появления электронных форм, заполнение которых занимает намного меньше времени, чем бумажные прототипы. Таким образом, с переходом на электронный стандарт хранения информации изменились многие аспекты разработки обслуживающего данный процесс программного обеспечения. Начиная с примитивных перфокарт, было положено начало для создания таких баз данных, какими мы привыкли их видеть сегодня. Первые базы данных писались под маломощные процессоры преимущественно на языке COBOL (1959 г.). Такие базы данных имели ограниченный функционал, и, как правило, могли использоваться и создаваться только имеющими определенный навык в сфере моделирования БД программистами. С течением времени и вкупе с развитием языков программирования, создание баз данных стало более доступно широкому пользователю. В наши дни создание простейшей базы данных обуславливается только знанием какого-либо языка программирования, не всегда объектно-ориентированного. Зачастую, достаточно базовых знаний языка Pascal. С развитием языков программирования тесно развивались и методы моделирования. Как отмечает Георгий Калянов [1], одним из наиболее перспективных методов разработки, направленных на упрощение создания бизнес процессов (БП) и баз данных (БД), являются CASE-средства для моделирования ПО.
Основными преимуществами CASE-разработки можно отметить:
· Наглядность;
· Модели позволяют проектировать базы данных с большим количеством объектов и атрибутов;
· Автоматическое создание документации на основе разработанного проекта.
· Отображение зависимостей внутри проекта.
· Широкий спектр объектов проекта: данные, классы, структуры, диаграммы, таблицы.
· Применимость метода разработки на множестве языков программирования.
К перечисленному выше перечню стоит добавить, что для интеграции с языками программирования создано достаточно много сред разработки CASE-проектов. При этом, сколь удобной ни была бы разработка по данному методу, не каждому подойдет определенная среда программирования. Прежде всего, нельзя забывать, что инструмент применяется пользователем, потребности которого разнообразны и не всегда обоснованы, но служит он достижению целей конкретной методологии. Именно в этом контексте следует рассматривать фразу С. Бира: «Прилагательные «хороший» или «плохой» в большей мере относятся к пользователям, чем к используемой ими технике» [2]. В таком случае, что же используют разработчики при моделировании баз данных? Видов программного обеспечения бесчисленное множество, мы рассмотрим отличительную черту самого процесса разработки — использование UML-диаграмм.
UML (Unified Modeling Language — унифицированный язык моделирования) — язык графического описания для объектного моделирования в области разработки программного обеспечения. Ниже представлен интерфейс программы NetBeans IDE и построенная UML — диаграмма проекта банковского счета.

Рисунок 1. NetBean IDE
Как видно, в блоке Bank Account присутствует множество заполняемых полей, при этом зависимый блок History отображает банковскую историю по переводам (transaction), набор диалоговых функций getMsg и setMsg, а также функцию increment Transaction, увеличивающую значение переведенных средств. Также следует обратить внимание на пометку “interface” Account. Данный блок является диалоговым окном для взаимодействия с пользователем. Здесь, как можно заметить, отображены функции вывода текущего баланса, получения номера счета, депозитной возможности клиента и тип его счета (кредит/дебет). При этом кодогенерация функций, генерация документации проекта происходит автоматически, все версии проекта при редактировании хранятся в репозитарии, вся документация хранится там же.
Посмотрим на пример, более близкий к среднестатистическому разработчику: возьмем встроенный в MS Visual Studio 2010 UML-редактор. В Visual Studio UML перекочевал относительно недавно. Первые попытки отображения зависимости классов были предприняты в версии 2008-го года. В версии VS 2010 появился редактор диаграмм классов, схемы активности, документы графов, диаграммы последовательностей. Такой набор инструментов позволяет произвести полноценную визуализацию программы, отобразить зависимость классов, структурировать построение проекта. Однако, полноценного UML-редактора у Microsoft не получилось. В данном продукте отсутствует возможность автоматической сборки машинного кода. Без Visualization and Modeling Feature Pack заполнение функций производится вручную [3].

Рисунок 2. Заполнение функций
Таким образом , такой мощный инструмент , как редактор UML диаграмм, в Visual Studio трансформирован в обычный обработчик XML-файла с набором диаграмм и объектов, где создание баз данных сводится к набору кода самостоятельно. Можно сделать вывод, что грамотная реализация среды разработки CASE-проектов позволяет во многом автоматизировать рабочий процесс программиста. На это и было нацелено создание UML. Стоит отметить, что модель «диаграмма-код» и обратная модель «код-диаграмма» требуют определенных навыков понимания программного кода и интерпретации диаграмм.
Основной задачей разработчика в данном случае является не столько знание языка программирования, а понимание связей между сущностями проекта, оформление этих связей в надлежащем виде. Создание инфологической модели требует дополнительной квалификации разработчика, понимания пространственно-логического построения проекта. Реализацию двойственных связей и построения исключительно логико-графической модели проекта можно рассмотреть на примере создания учебных планов для ВУЗов:
Предметная область задачи.
Вы работаете в высшем учебном заведении и занимаетесь организацией факультативов. В вашем распоряжении имеются сведения о студентах, включающие стандартные анкетные данные (фамилия, имя, отчество, адрес, телефон). Преподаватели вашей кафедры должны обеспечить проведение факультативных занятий по некоторым предметам. По каждому факультативу установлены определенное количество часов и вид проводимых занятий (лекции, практика, лабораторные работы). В результате работы со студентами у вас появляется информация о том, на какие факультативы записался каждый из них. Существует некоторый минимальный объем факультативных предметов, которые должен прослушать каждый студент. По окончании семестра вы заносите информацию об оценках, полученных студентами на экзаменах.
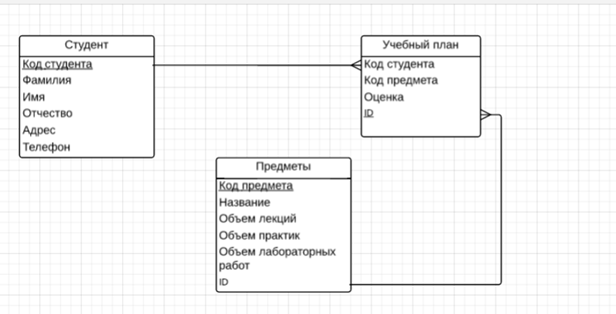
Рисунок 3. Базовая модель поставленной задачи
Развитие постановки задачи.
Теперь ситуация изменилась. Выяснилось, что некоторые из факультативов могут длиться более одного семестра. В каждом семестре для предмета устанавливается объем лекций, практик и лабораторных работ в часах. В качестве итоговой оценки за предмет берется последняя оценка, полученная студентом.
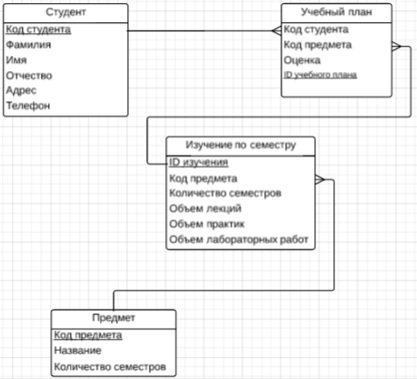
Рисунок 4. Модель после развития постановки задачи
Сущности.
· Студенты (Код студента, Фамилия, Имя, Отчество, Адрес, Телефон). Предметы (Код предмета, Название, Объем лекций, Объем практик, Объем лабораторных работ).
· Учебный план (Код студента, Код предмета, Оценка).
Двустороннее описание всех связей между сущностями по схеме:
· Один учебный план должен длиться более одного семестра.
· В один семестр должен входить один учебный план.
· Один студент должен обучаться по нескольким учебным планам.
· Один учебный план должен составляться для определенного студента.
· Один учебный план должен включать в себя один предмет.
· Один предмет должен содержаться в нескольких учебных планах.
Данный пример был реализован при помощи программы для создания инфологических диаграмм проектов LucidChart. Этот пример наглядно демонстрирует важность логического мышления, не исключая при этом знания языка программирования для создания базы данных без помощи средств автоматической генерации кода. Обязанностью современных разработчиков совмещать логическое мышление и анализ проектов с навыками программирования и правки кода осложняется процесс освоения перспективных возможностей, которые предоставляет CASE-подход к разработке новых продуктов. Правка программиста необходима на всех стадиях разработки проекта, так как стандартный набор генерируемых функций не всегда подходит для решения поставленных задач. И правка сгенерированного кода должна быть завершающим аккордом в создании логически полноценной модели разрабатываемого продукта.
Список литературы:
1. http://www.osp.ru/cio/2001/03/171683.
2. (в кн: Бир С. Мозг фирмы. — М.: Радио и связь, 1993. 416 с.).
3. http://softwarepeople.ru/blog/2010/08/08/uml_drawing_tools/.
