МОДЕЛЬ ИНТЕГРАЦИИ НЕЙРОСЕТЕВОГО СЛОЯ ОБРАБОТКИ ДАННЫХ С РЕЛЯЦИОННЫМИ И НЕРЕЛЯЦИОННЫМИ СУБД В РАСПРЕДЕЛЕННЫХ ВЕБ-СЕРВИСАХ
Конференция: XCVII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»
Секция: Информатика, вычислительная техника и управление

XCVII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»

МОДЕЛЬ ИНТЕГРАЦИИ НЕЙРОСЕТЕВОГО СЛОЯ ОБРАБОТКИ ДАННЫХ С РЕЛЯЦИОННЫМИ И НЕРЕЛЯЦИОННЫМИ СУБД В РАСПРЕДЕЛЕННЫХ ВЕБ-СЕРВИСАХ
A DATA-PROCESSING NEURAL LAYER FOR MIXED DATABASE ARCHITECTURES IN DISTRIBUTED WEB APPLICATIONS
Bulatovich Alexander Vladimirovich
MSc alumnus, Omsk State Transport University (OSTU), Russia, Omsk
Аннотация. В статье рассматривается проектно-методическая модель интеграции нейросетевого слоя обработки данных с реляционными и нереляционными СУБД в распределенных веб-сервисах. Цель работы состоит в описании потоков данных между СУБД, API, векторным хранилищем и нейросетевым слоем. Результатом являются структурная схема, уточненная таблица компонентов и проект регламента, практическая реализация и тестирование отнесены к следующему этапу исследования.
Abstract. The article considers a design-methodological model for integrating a neural network data processing layer with relational and non-relational DBMS in distributed web services. The purpose of the work is to describe data flows between DBMS, API, vector storage and the neural network layer. The results are a structural scheme, a refined component table and a draft regulation, practical implementation and testing are assigned to the next stage of the research.
Ключевые слова: веб-сервис, база данных, СУБД, PostgreSQL, MongoDB, нейросетевой слой, векторное хранилище, системный анализ, обработка информации.
Keywords: web service, database, DBMS, PostgreSQL, MongoDB, neural network layer, vector storage, systems analysis, information processing.
Интернет-сервисы на сегодняшний день стали набором связанных программных контуров. В одном контуре обрабатывается запрос пользователя, в следующем хранятся данные, дальше выполняется поиск, формируется ответ. На практике рядом работают серверная логика, API, базы данных разных типов, очереди, кэширование. Вопрос интеграции дополнительного нейросетевого слоя удобнее рассматривать через движение данных внутри веб-сервиса, а не через описание одной базы данных или одной модели. Работа имеет проектно-методический характер: она описывает архитектурную модель, а не уже внедренный программный комплекс.
В статье будут кратко рассмотрены основные варианты хранения данных в распределенных веб-сервисах. Притом взаимодействие реляционных и нереляционных СУБД с нейросетевым слоем будет рассмотрено более подробно, поскольку именно эти технологии становятся основой интеллектуального взаимодействия с данными в интернете.
Распределенные веб-сервисы более сложны – отдельные функции таких сервисов выполняются разными модулями и микросервисами. Их разработка и эксплуатация требуют применения дополнительного программного обеспечения: веб-сервер, backend-фреймворк, брокер сообщений, реляционная СУБД, нереляционная СУБД, кэш, система мониторинга, а также сервис нейросетевой обработки данных.
При разработке динамических информационных веб-сервисов СУБД выступают одним из основных компонентов хранения и обработки данных. Реляционные СУБД используются для хранения данных, структура которых заранее понятна: пользователи, роли, заказы, платежи, документы, права доступа, связи между сущностями. В качестве примера можно привести PostgreSQL и MySQL.
Плюсом реляционных СУБД является возможность строгого описания структуры данных, использования SQL, транзакций, индексов и ограничений. Это особенно важно для данных, где ошибка может привести к неправильной выдаче прав, неправильному статусу заказа, потере связи между документами или нарушению целостности информации.
Минус реляционных СУБД – работа с гибкими и часто меняющимися данными может быть осложнена. Если данные представляют собой документы, логи, события, пользовательские настройки, историю действий и другие структуры, которые не всегда удобно приводить к таблицам, то использование только реляционной СУБД становится менее рациональным.
Нереляционные СУБД используются для хранения документов, событий, логов, кэша, гибких пользовательских данных и других структур, которые сложно заранее привести к одной схеме. К примеру, MongoDB позволяет хранить данные в виде документов, близких к JSON-структуре [4].
Плюсом нереляционных СУБД является гибкость хранения данных и возможность быстрее подстраивать структуру под изменяющиеся требования веб-сервиса. Минус таких СУБД – необходимость более внимательно контролировать согласованность, дублирование данных и связи между объектами.
Динамические веб-сервисы, работающие с несколькими СУБД, формируются из совокупности функциональных и информационных компонентов (навигационные элементы, содержимое страниц, пользовательские комментарии, рекомендательные блоки, документы, уведомления, заказы, логи и т. д.), состав которых формируется в момент обращения пользователя к соответствующему ресурсу или API-методу. Текстовые материалы, адреса графических файлов, учетные записи пользователей, хэши паролей, сведения о пользовательских категориях, а также данные документов и обращений могут храниться в базах данных такого веб-сервиса.
Отдельного внимания заслуживает нейросетевой слой обработки данных. Его не следует рассматривать как замену СУБД. СУБД хранит данные, обеспечивает связи, транзакции, права доступа и целостность. Нейросетевой слой получает данные из СУБД, преобразует их в признаки, строит embeddings, ищет похожие фрагменты, классифицирует запросы и помогает возвращать пользователю более подходящий результат.
В данной работе нейросетевой слой понимается как программный модуль смысловой обработки данных: он получает подготовленные фрагменты и возвращает результат поиска или классификации. Вычислительный контур шире: в него входят API, СУБД, сервис синхронизации, векторное хранилище и сам нейросетевой слой. Такое разграничение позволяет не смешивать отдельный модуль обработки с общей схемой движения данных.
Для предлагаемой модели важно заранее определить, какие потоки данных вообще могут участвовать в нейросетевой обработке. Одни сведения относятся к основной транзакционной части сервиса, другие удобнее хранить как документы или события, третьи используются как справочная база, четвертые должны оставаться вне смыслового индекса. Такое разграничение снижает вероятность того, что в обработку попадут материалы без технической необходимости или без понятного назначения.
Более устойчивым вариантом представляется не прямое подключение модели к хранилищам, а промежуточный контур подготовки данных. Он получает записи из реляционной и нереляционной части системы, приводит их к единому формату, отбрасывает лишние поля, разбивает длинные материалы на удобные фрагменты и передает в векторное хранилище только подготовленные элементы. За счет этого сама модель работает не с сырым содержимым баз, а с предварительно обработанным массивом.
При этом наличие нейросетевой обработки само по себе не делает данные лучше. Если в системе накоплены старые карточки, неточные описания, повторяющиеся документы или записи с неполными признаками, то такой материал будет влиять и на результат смыслового поиска. Поэтому качество ответа зависит не только от выбранной модели, но и от порядка ведения базы данных, обновления документов, очистки дублей и фиксации источника каждого фрагмента.
Уменьшить издержки на обработку данных помогает разделение задач между СУБД и нейросетевым слоем. Реляционная СУБД используется для точных и транзакционных операций, нереляционная СУБД – для гибких документов и событий, векторное хранилище – для поиска похожих фрагментов, а нейросетевая модель – для обработки смысла запроса пользователя.
При выборе между пакетной выгрузкой данных раз в сутки и событийной синхронизацией, при внедрении стоит предпочитать комбинированный вариант из-за его универсальности. Пакетная выгрузка подходит для справочных данных и статей, а событийная синхронизация подходит для данных, которые часто изменяются.
Маршрут запроса в проектируемом веб-сервисе можно представить как последовательное прохождение нескольких технических узлов. Сначала пользователь работает с интерфейсом, затем backend принимает запрос и определяет, какие данные нужны для ответа. После этого сервис может обратиться к реляционной СУБД за точными сведениями, к нереляционной СУБД за документами или к векторному хранилищу за похожими фрагментами. Итоговый ответ формируется уже на уровне основного приложения, где объединяются результаты разных источников.
В рамках предлагаемой модели была проанализирована схема взаимодействия реляционной СУБД, нереляционной СУБД, API, векторного хранилища и нейросетевого слоя. Структурная модель потоков данных представлена на рисунке 1.
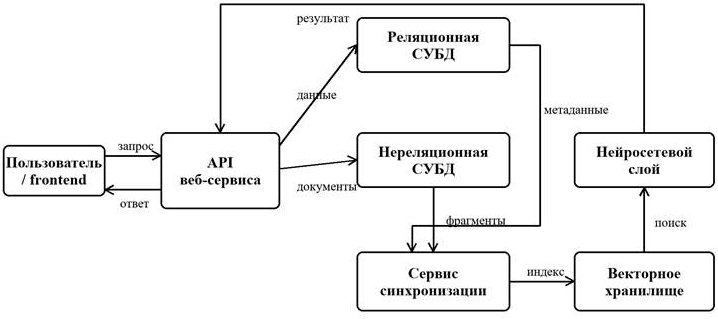
Рисунок 1. Структурная схема потоков данных между компонентами веб-сервиса
Состав основных компонентов модели представлен в таблице 1.
Таблица 1.
Компоненты взаимодействия СУБД и нейросетевого слоя в веб-сервисе
|
Элемент модели |
Назначение этого элемента |
Существенная проблема |
|
Реляционная СУБД |
Пользователи, заказы, роли, права доступа, связи между сущностями |
Не подходит для хранения гибких документов, смысловых признаков |
|
Нереляционная СУБД |
Документы пользователей, события, логи |
Сложнее контролировать согласованность и связи между элементами |
|
Сервис синхронизации |
Выгрузка данных |
Устаревание индекса |
|
Векторное хранилище данных |
Embedding-представления семантический поиск, ссылки на источники, метаданные |
Риск попадания лишних или устаревших данных в индекс |
|
Нейросетевая модель |
Поиск похожих частей, подсказки пользователю, классификация |
Потенциальный риск ошибочного результата |
|
API веб-сервиса |
Проверка прав доступа пользователя, выдача результата |
Можно обойти бизнес-логику при неправильной настройке |
Векторный индекс не должен превращаться в копию БД. Следует для каждого фрагмента хранить источник, тип материала, дату обновления, метаинформацию о доступе. Это дает возможность использовать конкретный фрагмент при формировании ответа.
Для проверки модели предложены два сценария: обычное обращение к БД и обращение к связке БД, векторного хранилища и нейросетевого слоя. Сравниваются скорость ответа, полнота найденных материалов, число нерелевантных фрагментов и удовлетворенность пользователя ответом.
Итогом работы является проект регламента обработки данных: что индексировать сразу, что очищать, что обновлять по расписанию или событию, а что оставлять только в основной СУБД.
