Коммутационное устройство с параллельно-конвейерной диспетчеризацией пакетов для матричных мультипроцессоров
Конференция: XXVI Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»
Секция: Информатика, вычислительная техника и управление

XXVI Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»

Коммутационное устройство с параллельно-конвейерной диспетчеризацией пакетов для матричных мультипроцессоров
Igor Zotov
full Doctor of Engineering Sciences, Full Professor, Southwest State University, Kursk, Russia
Mohammed Agmal Gamil Abdo
PhD Student, Southwest State University, Kursk, Russia
Аннотация. Рассмотрена задача совершенствования архитектуры коммутационных устройств матричных мультипроцессоров. Предложена структурно-функциональная организация коммутационного устройства с буферизованным матричным переключателем, реализующего новый параллельно-конвейерный способ диспетчеризации пакетов с учетом времени их пребывания в буферах. Показано преимущество устройства перед аналогами по пропускной способности на 1.2-3.8% и по вносимой задержке до 5 раз.
Abstract. The problem of developing an enhanced packet switch architecture for mesh-connected multiprocessors is considered. The structural and functional organization of a buffered crossbar switch with a novel parallel pipelined packet scheduler taking into account the time packets waste being locked in the buffers is proposed. The switch is shown to attain 1.2-3.8% higher throughput and up to 5 times lower delay compared to similar crosspoint-buffered devices.
Ключевые слова: матричный мультипроцессор; коммутатор пакетов; буферизованный переключатель; параллельно-конвейерная диспетчеризация.
Keywords: mesh-connected multiprocessor; packet switch; buffered crossbar; parallel pipelined packet scheduling.
Матричные мультипроцессоры (ММП) – один из перспективных подклассов параллельных вычислительных систем, способных эффективно решать как отдельные сложные сильно связанные задачи, так и комплексы независимых или слабо связанных задач [1]. В основе архитектуры ММП лежит множество идентичных процессорных модулей (ядер), объединенных коммуникационной сетью с матричной топологией [2-6].
Коммуникационная сеть (КС) является важнейшей составляющей матричного мультипроцессора. От ее пропускной способности и вносимой задержки зависит время передачи данных между процессорами (коммуникационная задержка), длительность циклов обращения к распределенной памяти, что непосредственно влияет на производительность ММП. КС ММП представляет собой матрицу идентичных коммутационных устройств, каждое из которых соединено со своими ближайшими соседями согласно топологической структуре сети.
Коммутационные устройства (КУ), применяемые в современных мультипроцессорах, чаще всего используют режим пакетной коммутации (packet switching) [2, 4, 6], реже – схемную коммутацию (circuit switching), отдельно либо как дополнение к пакетной коммутации [7, 8]. Наиболее распространенными способами построения КУ ММП являются коммутаторы с виртуальными выходными очередями (virtual output queued switch – VOQ-коммутатор), позволяющие достичь максимума пропускной способности [9, 10]. Интересным решением также является коммутатор с простыми (не-VOQ) входными FIFO-буферами и буферизованным выходным матричным переключателем [11, 12]. Он обладает на порядок меньшей аппаратной сложностью по сравнению с VOQ-коммутаторами, но, тем не менее, обеспечивает асимптотическую пропускную способность до 100% для многих видов входящего трафика. Кроме того, он не требует повышенной скорости работы переключателя, что является необходимым условием стабильной работы VOQ-коммутаторов без буферизации коммутирующей части. В данной работе рассматривается разновидность такого коммутационного устройства.
Предлагаемое КУ отличается использованием нового способа параллельно-конвейерной диспетчеризации пакетов с учетом времени их пребывания в буферной памяти. Теоретические основы построения устройства, а также некоторые результаты исследования его характеристик изложены в работах [13-15]. В настоящей статье обсуждаются ранее не публиковавшиеся результаты сравнительной оценки пропускной способности (throughput) и задержки (delay) разработанного КУ. В качестве ближайших аналогов взяты коммутаторы с буферизованным переключателем, реализующие равновероятную (BS-uniform) и круговую (BS-round-robin) диспетчеризацию пакетов [11, 12].
Структурная схема разработанного устройства изображена на рис. 1.

Рисунок 1. Структурная схема разработанного КУ
Устройство содержит n буферных блоков – FIFO-буферов (ББ1, ББ2, …, ББn, где n – число входов/выходов КУ), составляющих входной слой буферизации (СБ), n блоков маршрутизации (БМ1, БМ2, …, БМn), образующих слой маршрутизации (СМ), матрицу регистров (МР) – буферизованный переключатель, объединяющий ![]() регистровых ячеек (РЯ11, РЯ12, …, РЯ1n, РЯ21, РЯ22, …, РЯ2n, …, РЯn1, РЯn2, …, РЯnn), блок управления матрицей регистров (БУМР), содержащий n независимых блоков управления строками МР (БУС1, БУС2, …, БУСn), генератор адреса (ГА) и блок синхронизации (БС).
регистровых ячеек (РЯ11, РЯ12, …, РЯ1n, РЯ21, РЯ22, …, РЯ2n, …, РЯn1, РЯn2, …, РЯnn), блок управления матрицей регистров (БУМР), содержащий n независимых блоков управления строками МР (БУС1, БУС2, …, БУСn), генератор адреса (ГА) и блок синхронизации (БС).
Назначение блоков разработанного КУ заключается в следующем. Буферный блок ББi (![]() ) необходим для организации очереди пакетов, приходящих на вход Ii. Блок маршрутизации БМi (
) необходим для организации очереди пакетов, приходящих на вход Ii. Блок маршрутизации БМi (![]() ) используется для определения номера выхода Oj (
) используется для определения номера выхода Oj (![]() ), на который следует выдать пакет из ББi согласно заданному алгоритму маршрутизации. Матрица регистров (МР) обеспечивает временную буферизацию и перераспределение множества пакетов, поступающих из ББ1, ББ2, …, ББn, на выходы O1, O2, …, On в соответствии с разработанным способом диспетчеризации пакетов. Блок управления матрицей регистров (БУМР) обеспечивает согласованное функционирование матрицы регистров, ее взаимодействие со слоем буферизации. Генератор адреса (ГА) необходим для формирования адреса текущего устройства в топологической структуре ММП. Блок синхронизации (БС) предназначен для координации работы всех остальных блоков устройства.
), на который следует выдать пакет из ББi согласно заданному алгоритму маршрутизации. Матрица регистров (МР) обеспечивает временную буферизацию и перераспределение множества пакетов, поступающих из ББ1, ББ2, …, ББn, на выходы O1, O2, …, On в соответствии с разработанным способом диспетчеризации пакетов. Блок управления матрицей регистров (БУМР) обеспечивает согласованное функционирование матрицы регистров, ее взаимодействие со слоем буферизации. Генератор адреса (ГА) необходим для формирования адреса текущего устройства в топологической структуре ММП. Блок синхронизации (БС) предназначен для координации работы всех остальных блоков устройства.
Устройство работает циклами, каждый из которых включает 4 шага.
1. Определение направлений выдачи пакетов, находящихся в головных регистрах блоков ББi (![]() ), согласно заданному алгоритму маршрутизации.
), согласно заданному алгоритму маршрутизации.
2. Перенос в МР всех пакетов, которым соответствуют свободные регистры, и сдвиг всех очередей в буферных блоках, откуда были считаны пакеты.
3. Анализ способа размещения множества пакетов в МР и построчное определение порядка их выдачи с учетом продолжительности пребывания в матрице и входных буферах.
4. Выдача выбранного подмножества пакетов из МР на выходы устройства и освобождение соответствующих регистров матрицы.
Исследование функционирования разработанного КУ, оценка его пропускной способности, вносимой задержки и сопоставление полученных оценок с такими же показателями аналогичных коммутаторов выполнялись на основе имитационного моделирования в среде Visual QChart Simulator / PPP Switch Simulator [15]. В ходе машинных экспериментов рассматривались 2 наиболее распространенных варианта входящего трафика: 1) равномерно распределенный трафик Бернулли (Bernoulli uniform traffic); 2) асимметричный трафик Бернулли (hot spot Bernoulli traffic). Число входов/выходов устройства n и параметр распределения Бернулли p, определяющий интенсивность трафика, варьировались. Значения n выбирались из диапазона от 5 до 1000, что соответствует как практически значимым, так и перспективным случаям; значения p брались в пределах от 0.1 до 1 с шагом 0.1.
На рис. 2 изображены полученные в результате экспериментов графики зависимости пропускной способности КУ x от числа входов/выходов n (при малых n). Анализ полученных зависимостей показывает, что минимальная пропускная способность разработанного устройства составляет около 0.78 и соответствует ![]() (случаи
(случаи ![]() не принимались во внимание, поскольку не свойственны мультипроцессорам рассматриваемого класса). Согласно рис. 2, при малых n пропускная способность КУ примерно на
не принимались во внимание, поскольку не свойственны мультипроцессорам рассматриваемого класса). Согласно рис. 2, при малых n пропускная способность КУ примерно на ![]() выше, чем у коммутаторов с равновероятной (BS-uniform) и круговой (BS-round-robin) диспетчеризацией пакетов.
выше, чем у коммутаторов с равновероятной (BS-uniform) и круговой (BS-round-robin) диспетчеризацией пакетов.
На рис. 3 представлены графики зависимости пропускной способности КУ x от n при ![]() . Поскольку ошибка малой выборки при
. Поскольку ошибка малой выборки при ![]() составила менее 1%, планки погрешностей на рис. 3 условно не показаны. Из рис. 3 видно, что при больших n преимущество разработанного КУ ощутимо выше, чем при малых n, и увеличивается до
составила менее 1%, планки погрешностей на рис. 3 условно не показаны. Из рис. 3 видно, что при больших n преимущество разработанного КУ ощутимо выше, чем при малых n, и увеличивается до ![]() % перед коммутатором с равновероятной диспетчеризацией (BS-uniform) и до
% перед коммутатором с равновероятной диспетчеризацией (BS-uniform) и до ![]() % перед устройством с круговой диспетчеризацией (BS-round-robin).
% перед устройством с круговой диспетчеризацией (BS-round-robin).
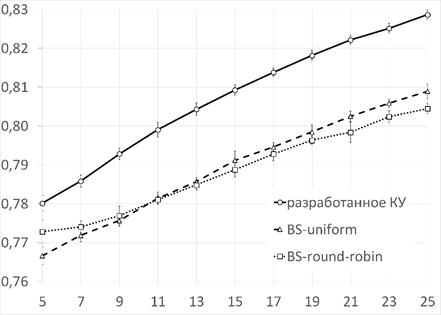
Рисунок 2. Графики зависимости пропускной способности КУ x от числа входов/выходов n для практически значимых n (погрешности соответствуют ![]() )
)

Рисунок 3. Графики зависимости пропускной способности КУ x от числа входов/выходов n при больших n
На рис. 4 и 5 приведены графики зависимости средней задержки КУ t (в тактах, равных времени прохождения пакета со входа на выход КУ без учета времени нахождения в буферах) от параметра распределения Бернулли p при ![]() и
и ![]() соответственно (поскольку погрешности малой выборки составили менее 1%, для упрощения планки погрешностей не показаны). Из представленных графиков видно, что при малой (
соответственно (поскольку погрешности малой выборки составили менее 1%, для упрощения планки погрешностей не показаны). Из представленных графиков видно, что при малой (![]() ) интенсивности потоков пакетов разработанное устройство не имеет преимуществ по величине задержки перед аналогами, однако уже при
) интенсивности потоков пакетов разработанное устройство не имеет преимуществ по величине задержки перед аналогами, однако уже при ![]() наблюдается выигрыш в
наблюдается выигрыш в ![]() %. Наибольшее преимущество устройства достигается при
%. Наибольшее преимущество устройства достигается при ![]() и составляет примерно до 5 раз.
и составляет примерно до 5 раз.
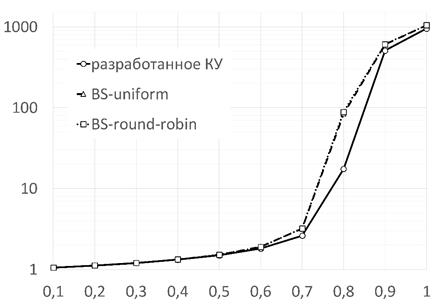
Рисунок 4. Графики зависимости средней задержки КУ t (в тактах) от параметра распределения Бернулли p при ![]()
В ходе машинного эксперимента также было проведено детальное изучение поведения задержки разработанного устройства ![]() при различном числе его входов/выходов n. В результате были получено семейство графиков, приведенных на рис. 6 (за единицу измерения здесь взят микротакт – один период следования импульсов встроенного генератора в составе БС, равный 1/3 такта).
при различном числе его входов/выходов n. В результате были получено семейство графиков, приведенных на рис. 6 (за единицу измерения здесь взят микротакт – один период следования импульсов встроенного генератора в составе БС, равный 1/3 такта).

Рисунок 5. Графики зависимости средней задержки КУ t (в тактах) от параметра распределения Бернулли p при ![]()
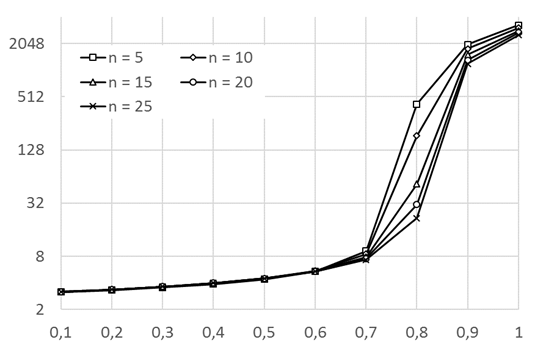
Рисунок 6. Графики зависимости задержки прохождения пакета через КУ ![]() от параметра p распределения Бернулли p для
от параметра p распределения Бернулли p для ![]()
Из рис. 6 видно, что при ![]() задержка
задержка ![]() практически не зависит от числа входов/выходов КУ и изменяется от минимального значения
практически не зависит от числа входов/выходов КУ и изменяется от минимального значения ![]() микротактов (
микротактов (![]() ) до
) до ![]() микротактов (
микротактов (![]() ). Дальнейшее увеличение параметра p приводит к резкому повышению
). Дальнейшее увеличение параметра p приводит к резкому повышению ![]() , которое будет тем резче, чем меньше значение n. Однако установлено, что кратковременное повышение p до уровней выше
, которое будет тем резче, чем меньше значение n. Однако установлено, что кратковременное повышение p до уровней выше ![]() (hot spot Bernoulli traffic) вполне допустимо и будет приводить лишь к небольшому временному повышению длины очередей пакетов и величины
(hot spot Bernoulli traffic) вполне допустимо и будет приводить лишь к небольшому временному повышению длины очередей пакетов и величины ![]() , которые затем стабилизируются при снижении нагрузки на КУ.
, которые затем стабилизируются при снижении нагрузки на КУ.
Проведенные машинные эксперименты также показывают, что в достаточно широком диапазоне значений интенсивности входящих потоков пакетов (![]() ) полное время прохождения пакета через КУ практически не зависит от числа входов/выходов n и не превышает
) полное время прохождения пакета через КУ практически не зависит от числа входов/выходов n и не превышает ![]() микротактов. При работе устройства на частоте 2 ГГц указанное время составило бы не более
микротактов. При работе устройства на частоте 2 ГГц указанное время составило бы не более ![]() нс, что отвечает скоростным требованиям современных ММП [2-6].
нс, что отвечает скоростным требованиям современных ММП [2-6].
