ВЛИЯНИЕ РАЗМЕРА И АРХИТЕКТУРЫ КЭШ-ПАМЯТИ НА ПРОИЗВОДИТЕЛЬНОСТЬ ПРОЦЕССОРА
Журнал: Научный журнал «Студенческий форум» выпуск №4(355)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №4(355)
ВЛИЯНИЕ РАЗМЕРА И АРХИТЕКТУРЫ КЭШ-ПАМЯТИ НА ПРОИЗВОДИТЕЛЬНОСТЬ ПРОЦЕССОРА
Современная компьютерная архитектура развивается в условиях жесткого дисбаланса производительности между центральным процессором и основной памятью. Согласно закону Мура, количество транзисторов на кристалле удваивалось каждые 18–24 месяца, что сопровождалось соразмерным ростом тактовых частот. Однако время доступа к динамической оперативной памяти (DRAM) улучшалось лишь на несколько процентов в год. Такое несбалансированное развитие привело к возникновению фундаментального барьера, известного в литературе как «стена памяти». В условиях отсутствия кэширования процессор был бы вынужден простаивать до 90% времени, ожидая завершения транзакций на шине памяти [1, с. 449].
Решение данной проблемы строится на иерархическом принципе: использовании нескольких уровней памяти с прогрессивно увеличивающимся объемом и уменьшающейся скоростью доступа. Верхние уровни интегрируются непосредственно в ядро процессора, обеспечивая минимальный расход времени за счет использования статической памяти (SRAM). Нижние уровни и внешняя память реализуются на базе более дешевой и плотной DRAM.
Эффективность кэш-памяти базируется на свойствах локальности программного кода. Временная локальность диктует необходимость сохранения недавно использованных данных, так как скорее всего в ближайших циклах произойдет повторное обращение к ним. Пространственная локальность предполагает, что при обращении к некоторому адресу, программа с высокой долей вероятности вскоре запросит данные из соседнего. Это свойство обосновывает передачу данных не отдельными ячейками, а блоками [2, с. 88].
Математическая модель оценки производительности системы памяти выражается формулой среднего времени доступа:
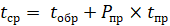
где 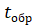 — время задержки при попадании в кэш,
— время задержки при попадании в кэш, 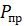 — частота промахов, а
— частота промахов, а 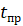 — штраф за промах.
— штраф за промах.
Исходя из этой формулы, оптимизацию возможно реализовать тремя способами: снижение вероятности отсутствия данных, уменьшение времени поиска в структуре кэша и ускорение процесса подкачки из нижестоящих уровней иерархии.
Выбор архитектуры отображения определяет баланс между стоимостью поиска и эффективностью использования объема. При прямом отображении каждый блок основной памяти имеет строго одну возможную позицию в кэше, что упрощает логику, но приводит к конфликтам в ситуации, когда две активные области программы претендуют на одну и ту же строку. Полностью ассоциативный кэш позволяет разместить данные в любой ячейке, исключая упомянутые конфликты, но требует дорогостоящих схем параллельного сравнения тегов. Множественно-ассоциативная архитектура является стандартом в современной индустрии и своеобразным компромиссом. Она группирует строки в наборы.
Анализ причин неэффективности кэширования принято проводить по трём видам промахов. Обязательные промахи представляют собой фундаментальное ограничение любой системы кэширования. Они возникают в момент первого обращения процессора к блоку данных, который ранее никогда не загружался в кэш. Поскольку память изначально пуста или не содержит данных конкретного процесса, первый запрос к любому адресу неизбежно приводит к промаху. Влияние обязательных промахов наиболее заметно в коротких программах или при частой смене контекста задач. Единственным эффективным методом борьбы с ними является аппаратная или программная предвыборка, которая позволяет загружать данные в кэш до того, как к ним поступит явный запрос от исполнительных устройств процессора.
Емкостные промахи напрямую связаны с физическим объемом кэш-памяти. Если совокупный объем всех блоков данных, к которым программа активно обращается в определенный промежуток времени, превышает вместимость кэша, некоторые блоки будут постоянно вытесняться. Когда процессору снова требуются эти данные, происходит промах, так как они были удалены для освобождения места под новые запросы. Проблема емкостных промахов решается либо увеличением физического размера кэша, что ограничено площадью кристалла и задержками сигнала, либо оптимизацией алгоритмов обработки данных в программном обеспечении, чтобы минимизировать размер рабочего набора в каждый момент времени.
Конфликтные промахи характерны для архитектур с прямым или множественно-ассоциативным отображением. Они возникают в ситуациях, когда кэш обладает достаточным общим объемом для хранения данных, но из-за ограничений логики отображения несколько блоков основной памяти претендуют на одну и ту же строку или набор строк в кэше [1, с. 544].
В современных многоядерных архитектурах выделяют промахи когерентности, возникающие в результате взаимодействия нескольких исполнительных ядер. Когда одно ядро производит запись по определенному адресу, копии этого блока данных в кэшах других ядер становятся неактуальными. Протоколы поддержания когерентности принудительно переводят эти копии в состояние «недействительно». При следующей попытке другого ядра прочитать эти данные возникнет промах когерентности, вынуждающий систему выполнить транзакцию по обновлению данных через общую шину или кэш последнего уровня [2, с. 560].
При заполнении кэша встает задача выбора строки для вытеснения. Наиболее эффективным признан алгоритм LRU — вытеснение наиболее давно использовавшегося блока. Однако его полная реализация в высокоскоростных кэшах затруднена из-за сложности учета, поэтому часто применяются алгоритмы на основе частоты использования.
Сокращение времени обращения реализуется через архитектурные приёмы, такие как виртуально индексируемые физически тегируемые кэши. Эта технология позволяет начинать поиск в кэше по младшим битам виртуального адреса одновременно с работой блока управления памятью, который транслирует виртуальный адрес в физический. К моменту готовности физического тега выборка из кэша уже завершена, и остается только выполнить операцию сравнения.
Для снижения штрафа за промах применяются неблокирующие кэши. В архитектурах с внеочередным исполнением команд процессор не останавливается при промахе в L1, а продолжает выполнять независимые инструкции. Технология «критическое слово первым» позволяет процессору возобновить работу сразу после получения искомого байта, не дожидаясь загрузки всей 64-байтной строки из ОЗУ.
Современный этап развития кэш-памяти характеризуется переходом к адаптивным механизмам. Внедряются интеллектуальные предсказатели, которые анализируют сложные паттерны доступа и заранее подкачивают данные. Последние исследования указывают на эффективность внедрения нейросетевых контроллеров непосредственно в логику кэша для динамического изменения политики замещения в зависимости от поведения конкретного приложения.
Также ведутся разработки в области использования новых материалов. Память на магнитных туннельных перехода и фазопеременная память рассматриваются как кандидаты на замену традиционной SRAM в кэшах третьего и четвертого уровней. Эти технологии обещают существенно большую плотность хранения данных при сохранении скоростей, близких к полупроводниковой логике, что позволит создавать кэши объемом в несколько гигабайт непосредственно на подложке процессора.
Эволюция кэш-памяти прошла путь от простых буферов до сложнейших многоуровневых систем с интеллектуальным управлением. На текущий момент именно подсистема памяти, а не чистая тактовая частота, является определяющим фактором реальной производительности в задачах анализа больших данных и искусственного интеллекта. Оптимизация программного кода под конкретные параметры кэш-иерархии остается одной из наиболее востребованных и сложных задач современного системного программирования.
