Методы обеспечения реферирования текстов
Журнал: Научный журнал «Студенческий форум» выпуск №24(45)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №24(45)
Методы обеспечения реферирования текстов
Аннотация. В эпоху информационных технологий огромную роль играет скорость восприятия и понимание читаемой информации. Рост количества статей, больших объемов текстов и данных создает необходимость использовать машинные методы извлечения, подсчета, обработки информации. Помимо необходимости извлечения современные задачи в сфере ИТ включают в себя также генерирование информации. Например, чат-боты, обработка изображений, прогнозирование результатов.
Ключевые слова: Нейронная сеть, машинное обучение, реферирование, глубинное обучение, Персептрон, Word2Vec.
Машинное обучение – одна из больших частей информатики, которая позволяет компьютерам возможность обучаться, не будучи явно запрограммированной.
Объектом исследования работы являются два основных комплекса связанных с обработкой естественного языка: математический и лингвистический методы под названием обработка естественного языка (NLP– natural language processing)
Предметом исследования является автоматическое реферирование текстов с учетом специфики ведения диалогов в социальной сети.
Основной задачей является формирование ряда практических методов, позволяющих обрабатывать текст. На данный момент тема исследования является одной из основных задач обработки естественного языка.
Основная цель реферирования - найти подмножество данных, которое содержит «информацию» всего набора и сделать краткий обзор текста - реферат. В рамках обработки текста в роли набора выступают слова, предложения, абзацы и т.д. Примерами являются поисковые системы, онлайн-переводчики и т.д.
Реферат создается путем поиска наиболее информативных предложений в тексте. Существует два основных метода автоматического реферирования:
1. Экстрактный - извлекающий метод
2. Абстрактный метод
Методы экстракции находят множество существующих слов, фраз или предложений в исходном тексте для дальнейшего формирования реферата. В большинстве случаев такие методы используют алгоритмы, рассчитывающие частоту нахождения слов в тексте.
Абстрактные методы создают внутреннее представление истиной информации текста, а затем используют определённые алгоритмы генерирования естественного языка для создания реферата, который будет понятнее человеку.
На сегодняшний день все исследования построены экстрактивных методах. Абстрактные методы требуют экспериментального подхода с использованием современного программного обеспечения направленного на машинное обучение [1].
Цель исследования – разработать программный модуль осуществляющий реферирование текста с учётом специфики ведения диалогов в социальной сети.
Задачи данного исследования:
1. Исследовать существующие методы по разработке программного обеспечения для реферирования текстов.
2. Рассмотреть существующие алгоритмы и методы, которые используются для обработки текстовой информации
3. Разработать модель программы, осуществляющей реферирование текстов, представленных диалогом в социальной сети.
4. Подготовить отчет о работе разработанной программы и проанализировать результаты.
Реферирование - это процесс извлечения самой важной информации из источника (или источников) для создания сокращенной версии для конкретного пользователя (или пользователей) и задачи [2].
Одним из примеров создания реферата можно рассмотреть длинную новостною статью, из которой можно выделить много коротких текстовых сводок, которые встречаются каждый день.
Рассмотрим методы реферирования, которые основанных на нейронных сетях:
1. Экстракция - производит выбор фраз и предложений из источника для формирования главной мысли всего сказанного заключается в распределении фраз по важности.
2. Абстрагирование – генерация абсолютно новых слов, фраз и предложений для выделения смысла исходного документа (источника). Более сложный подход, приближен к человеческому (выбор и сжатие содержимого из исходного документа). Для решения вопросов, связанных с абстрагирующим реферированием текста, лучше всего подходит совокупность методов, называемыми Deep Learning или глубинное обучение.
3. Глубинное обучение (англ. Deep learning) — уровень технологий машинного обучения, характеризующий качественный прогресс, возникший после 2006 года в связи с нарастанием вычислительных мощностей и накоплением опыта. Методы глубинного обучения продемонстрировали очень хорошие результаты для реферирования различных текстов (автоматического машинного перевода, в частности модель sequence to sequence – последовательность к последовательности). Такая модель полностью подходит для проведения операции реферирования различных текстов.
4. Искусственная нейронная сеть. Для изучения нейронной сети необходимо понимать, что такое искусственный нейрон и принцип его работы. Самым распространенным типом искусственного нейрона, является персептрон.
Перцептрон принимает несколько двоичных входов x1, x2, ... и производит один двоичный выход (рис. 1).
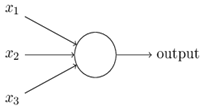
Рисунок 1. Схема перцептрона
Персептрон имеет три входа: x1, x2, x3. Фрэнк Розенблатт предложил простое правило для вычисления результата. Он представил веса, w1, w2, как действительные числа, выражающие важность соответствующих входных данных для вывода. Выход нейрона может быть 0 или 1 и определяется тем, является ли взвешенная сумма Σjwjxj меньше или больше некоторого порогового (threshold) значения. Подобно весам, порог представляет собой действительное число, которое является параметром нейрона (рис. 2).
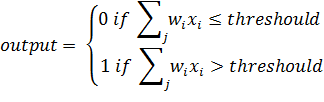
Рисунок 2. Формула активации нейрона
Это основная математическая модель. Основным простым способом представления персептрона, является тем, что это устройство, которое принимает решения, взвешивая доказательства.
5. Представление слов в качестве векторов. Выделить слова в чистом виде невозможно, т.к. нейросеть воспринимает данные в формате цифр. Для решения данной проблемы необходимо, чтобы нейросеть воспринимала последовательность слов, существует несколько методов представления слов в многомерном цифровом пространстве.
6. Простые векторы совпадений. Анализ контекста, в котором используется слово, - это трансцендентное понимание, того как приблизится к реферированию текста. Механизм заключается в принятии во внимание того, какие слова окружают рассматриваемое слово.
7. Word2Vec - это группа связанных моделей, которые используются для создания векторных представлений слов. Эти модели представляют собой небольшие двухслойные нейронные сети, которые обучаются реконструировать лингвистические контексты слов. Word2vec принимает в качестве своего ввода большой корпус текста и создает векторное пространство, обычно в несколько сотен измерений, причем каждому уникальному слову в корпусе присваивается соответствующий вектор в пространстве. Векторные представления расположены в векторном пространстве, так что слова, которые имеют общие контексты в корпусе, расположены в непосредственной близости друг от друга в пространстве (рис. 3).

Рисунок 3. Векторы слов
Это позволяет использовать семантическую связь слов, а также производить вычисления при помощи векторной алгебры.
Кроме использования нейронных сетей для реферирования текстов, возможно применение других алгоритмов и методов, которые позволяют сделать реферирования текста без использования нейросетей.
Таким образом, мы рассмотрели наиболее популярные методы реферирования текста на основе нейронных сетей.
©А.С.Дульнев, 2018
