Разработка веб приложения для автоматического анализа тональности текстов на основе методов машинного обучения
Журнал: Научный журнал «Студенческий форум» выпуск №22(73)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №22(73)
Разработка веб приложения для автоматического анализа тональности текстов на основе методов машинного обучения
Аннотация. Работа посвящена изучению существующих методов анализа сентиментальности текста, разработке и реализации веб-приложения для определения ключевого текста в комментариях и абзацах в социальных сетях. Эксперимент основан на наборах данных из порталов социальных сетей, таких как «Tengrinews.kz», «Nur.kz» и «Zakon.kz», которые анализируют тон сообщения, введенного пользователем. В этом исследовании, применяются модели метода машинного обучения; анализируется тон пользовательского ввода, с помощью которого мы можем получить социальное настроение людей. Тем самым показаны преимущества работы с вышеупомянутыми методами. Цель состоит в том, чтобы показать, где и как наивные Байесовские классификаторы могут обеспечить ценный анализ в процессе анализа текста.
Ключевые слова: сентиментальный анализ, краулер, набор данных, мусор, униграммы, биграммы, машинное обучение.
Вступление. С развитием интернет-сервисов и порталов каждый пользователь получил возможность высказать свое мнение посредством комментариев или голосования. Таким образом, возникла необходимость обрабатывать огромные объемы информации, чтобы определить позицию пользователей к конкретному объекту. Еще чаще пользователи оставляют отзывы и комментарии не на специализированных сайтах обратной связи, а в социальных сетях. Объем данных в социальных сетях слишком велик для ручной обработки, в связи с чем, была поставлена актуальная задача – разработать автоматический поиск и классифицировать комментарий и ответы.
Очевидно, что количество опубликованных обзоров, например, в социальных сетях достигает сотен тысяч, а обработка комментариев вручную - практическая нереальная задача. Например, «Твиттер» (Twitter) является одной из самых популярных социальных сетей. Количество активных пользователей составляет около 313 миллионов, и они оставляют около 500 миллионов сообщений в день. Большой набор используемых словарных, сленговых и грамматических ошибок усложняет задачу автоматического поиска и анализа текста.
В связи с этим широко используются такие области, как компьютерные науки, такие как анализ мнений и анализ настроений. Стало возможным автоматически получать или «выявлять» мнение, выраженное в тексте. Для этого использовались методы машинного обучения, более поздние методы стали основываться на использовании словарей тональных слов. Методы машинного обучения давно используются в задачах определения ключа, но их применение в сегменте социальных сетей началось сравнительно недавно.
Семантический анализ текста
Основная задача состоит в том, чтобы автоматически извлекать мнения из текстов, то есть определять, содержит ли этот текст субъективный компонент, и классифицировать тексты на основе тональности для двух (положительных и отрицательных) или более классов. Под тональностью здесь понимается эмоциональная оценка, выраженная автором в отношении какого-либо объекта. Зависимость значения тональности от предметной области.
Есть также проблемы в задаче определения ключа. Например, слово «непредсказуемый» может иметь положительное значение, но в сфере обслуживания клиентов это не так. При использовании методов обучения с учеником, алгоритм классификации, например, наивный Байесовский классификатор, генерирует значения тональности из обучающей выборки, поэтому для надлежащей классификации этого достаточно, чтобы обучающая и тестовая выборки имели общую предметную область. На практике пользовательские запросы не обязательно ограничены какой-либо одной областью, поэтому вы можете классифицировать текст в два этапа: сначала тематическая классификация документа, затем классификация ключа.
Сбор данных и классификация текстов.
Чтобы создать модель машинного обучения, нам нужно собрать огромное количество текстовых данных и примерно классифицировать их по своей природе. Нашим первым шагом является создание данных «DataSet», по которым в будущем наша модель будет тренироваться и обучаться, чтобы алгоритмы машинного обучения могли проводить семантический анализ текста в определенных входных данных. В качестве информационных ресурсов для эксперимента мы выбрали самые популярные и посещаемые порталы: www. tengrinew.kz, www. nur.kz и www. zakon.kz. Для каждого портала мы разработали «краулер», который собирает определенное количество новостей и комментарий для дальнейшей их классификации.
Чтобы заставить «краулер» работать для каждого портала, мы выполнили следующие шаги:
Шаг 1: изучить HTML-контент и архитектуру макета, принцип загрузки новостей с каждого портала;
Шаг 2: для каждого портала написать свой алгоритм загрузки и анализа данных в правильном порядке;
Шаг 3: разобрать функцию очистки ненужных слов «мусор» от текстов, загруженных с портала, для повышения эффективности и точности алгоритма машинного обучения;
Шаг 4: оптимизировать скорость загрузки и обработки данных с использованием языка SQL;
Шаг 5: Создать удобный интерфейс для просмотра, отображения статистики и управления данными после загрузки.
Шаг 6: проверить, исправить скорость обработки.
Далее мы будем вручную распределять текст по категориям: негативный, позитивный и нейтральный.
Мы распределили их в трех специальных папках: плохой, хороший и нейтральный (позитивный, негативный и нейтральный) в файловой системе.
Разработка модели машинного обучения
В качестве первого эксперимента мы выбрали наивный Байесовский классификатор. Наивный Байесовский классификатор - это простой классификатор, основанный на применении теоремы Байеса со строгими (наивными) предположениями о независимости. В зависимости от точного характера вероятностной модели, наивные Байесовские классификаторы могут быть обучены очень эффективно. Наивные Байесовские классификаторы хорошо масштабируются, для чего требуется ряд параметров, линейных по числу переменных (признаков / предикторов) в задаче обучения. Обучение максимального правдоподобия может быть выполнено путем оценки выражения в закрытой форме. Во многих практических приложениях метод максимального правдоподобия используется для оценки параметров наивных Байесовских моделей; другими словами, можно работать с наивной Байесовской моделью, не веря в Байесовскую вероятность и не используя Байесовские методы. Преимущество наивного Байесовского классификатора заключается в небольшом количестве обучающих данных, необходимых для оценки параметров, необходимых для классификации.
Нашей следующей задачей было разработать алгоритм, подобрать необходимые технологии для загрузки контента с портала. В связи с этим основным языком технологии выбран JAVA, поскольку он широко используется, и для него могут быть разработаны высокоскоростные веб-приложения с большой нагрузкой.
Мне пришлось использовать реализованный алгоритм Наивного Байеса, используя библиотеку WEKA.
С помощью наивного Байесовского классификатора я трансформирую модель, которую позже использую для определения текста. Обучающий алгоритм классификации или классификатор заключается в сообщении алгоритма примеров (объект, метка), размещенных в паре (х, у). Объект описывается некоторыми атрибутами, набором (или вектором) которых можно качественно отличить объект одного класса от объекта другого класса. В контексте задачи распознавания тональности вектор признаков может состоять из слов (униграмм) или пар слов (биграмм). Кроме того, метки будут именами (или серийными номерами) классов тональности: ОТРИЦАТЕЛЬНЫЕ, НЕЙТРАЛЬНЫЕ или ПОЗИТИВНЫЕ. Основываясь на примерах, мы ожидаем, что алгоритм сможет обучаться и обобщать до уровня предсказания неизвестной метки y 'вдоль вектора признаков x'.
В результате мы получаем обученную модель в виде сериализованного файла JAVA в формате «модель».
Использование краулера и определение семантики новостей
Кроме того, моя задача состоит в том, чтобы использовать ранее разработанный «Краулер», который сможет считывать текстовые данные с информационного портала, разрабатывать модуль, который поможет мне применить ранее разработанную модель и определить семантику каждого текста. Алгоритм модуля выглядит так:

Рисунок 1. Алгоритм определения семантики каждого текста
Обработанные данные и результаты я записываю в таблицу базы данных для каждого информационного портала, используя технологию hibernate 4.0 ORM. Между ними мы анализируем тональность предложения из комментариев, используя нашу наивную Байесовскую модель. Код реализации выглядит следующим образом:

Рисунок 2. Начальная подготовка к записи в базу данных и применение нашей модели для обработки текста
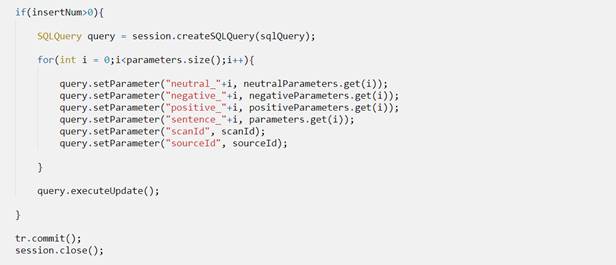
Рисунок 3. Запишите проанализированные данные в базу данных
После обработки данных мы сохраняем информацию в базе данных, а затем можем выработать статистику и получать определенные результаты.
Заключение
После этого эксперимента мы выучили наивный Байесовский алгоритм в машинном обучении для определения ключа текста в веб-порталах. Мы объединили «краулер» и алгоритм машинного обучения для разработки нашего веб-приложения. Наша следующая цель - протестировать другие алгоритмы машинного обучения для выбора наилучшего варианта, скорректировать модель алгоритма, точность результатов, визуализацию результатов в виде графиков и диаграмм, добавить еще несколько порталов для расширения диапазон поиска.
