Статья:




СРАВНИТЕЛЬНЫЙ АНАЛИЗ ВЕРТИКАЛЬНОГО И ГОРИЗОНТАЛЬНОГО МАСШТАБИРОВАНИЯ БАЗ ДАННЫХ НА ПРИМЕРЕ POSTGRESQL
Конференция: CCCXLI Студенческая международная научно-практическая конференция «Молодежный научный форум»
Секция: Технические науки
Выходные данные
Дубич Е.В., Щагин Д.В. СРАВНИТЕЛЬНЫЙ АНАЛИЗ ВЕРТИКАЛЬНОГО И ГОРИЗОНТАЛЬНОГО МАСШТАБИРОВАНИЯ БАЗ ДАННЫХ НА ПРИМЕРЕ POSTGRESQL // Молодежный научный форум: электр. сб. ст. по мат. CCCXLI междунар. студ. науч.-практ. конф. № 15(341). URL: https://nauchforum.ru/archive/MNF_interdisciplinarity/15(341).pdf (дата обращения: 01.08.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 3 голоса
Мне нравится3
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

CCCXLI Студенческая международная научно-практическая конференция «Молодежный научный форум»
СРАВНИТЕЛЬНЫЙ АНАЛИЗ ВЕРТИКАЛЬНОГО И ГОРИЗОНТАЛЬНОГО МАСШТАБИРОВАНИЯ БАЗ ДАННЫХ НА ПРИМЕРЕ POSTGRESQL
Дубич Евгений Васильевич
студент, Национальный исследовательский университет Высшая школа экономики, РФ, г. Москва
Щагин Дмитрий Владимирович
студент, Национальный исследовательский университет Высшая школа экономики, РФ, г. Москва
COMPARATIVE ANALYSIS OF VERTICAL AND HORIZONTAL DATABASE SCALING USING POSTGRESQL
Dubich Evgeniy Vasilievich
Student, National Research University Higher School of Economics, Russia, Moscow
Schagin Dmitry Vladimirovich
Student, National Research University Higher School of Economics, Russia, Moscow
Аннотация. В статье рассматриваются подходы к масштабированию баз данных на примере PostgreSQL. Целью работы является сравнительный анализ вертикального масштабирования и горизонтального масштабирования чтения с использованием read replica при росте нагрузки на систему. В рамках исследования было проведено тестирование трех конфигураций: базовой, вертикально масштабированной и горизонтально масштабированной. Сравнение выполнялось по показателям пропускной способности системы и средней задержки в сценариях с преобладанием операций чтения и при смешанной нагрузке. Полученные результаты показали, что обе масштабированные конфигурации существенно превосходят базовую. Сделан вывод о том, что выбор подхода к масштабированию должен определяться структурой нагрузки и требованиями к производительности системы.
Ключевые слова: PostgreSQL, базы данных, масштабирование баз данных, вертикальное масштабирование, горизонтальное масштабирование, read replica, производительность баз данных, пропускная способность, задержка, нагрузочное тестирование.
1. Введение
В условиях повсеместного распространения информационных систем критическую важность приобретает вопрос производительности и надежности баз данных. Рост числа пользователей, увеличение объема обрабатываемых данных и повышение интенсивности запросов приводят к росту нагрузки на системы управления базами данных. Этим объясняется практическая необходимость исследования методов масштабирования баз данных.
Одной из наиболее распространенных реляционных систем управления базами данных является PostgreSQL [1]. Данная СУБД активно используется в веб-приложениях, корпоративных системах, исследовательских и учебных проектах ввиду открытой модели распространения, надежности, расширяемости и наличия поддержки современных механизмов обработки данных. Вместе с тем с ростом нагрузки даже эффективно настроенный экземпляр PostgreSQL может сталкиваться с ограничениями пропускной способности и увеличением времени отклика, что делает актуальным использование масштабирования.
На практике для повышения производительности реляционных баз данных широко применяются два основных подхода: вертикальное и горизонтальное масштабирование [2]. Первый подход связан с увеличением вычислительных ресурсов узла, на котором развернута база данных. Второй подход ориентирован на распределение нагрузки между несколькими экземплярами базы данных. В рамках данной работы горизонтальное масштабирование рассматривается на примере метода read replica [3]. Каждый из указанных подходов имеет свои преимущества и ограничения, поэтому выбор между ними не является однозначным.
Вертикальное масштабирование удобно с точки зрения эксплуатации и администрирования, однако ограничено ресурсами одного узла. Использование read replica, напротив, потенциально позволяет эффективнее работать при высокой доле операций чтения, но сопровождается усложнением архитектуры системы. В связи с этим представляет интерес сравнительное исследование условий, при которых вертикальное масштабирование остается достаточным, и условий, при которых применение read replica оказывается более эффективным.
Целью данной работы является сравнительный анализ вертикального масштабирования и горизонтального масштабирования чтения с использованием read replica в PostgreSQL при росте нагрузки на систему. Для достижения этой цели рассматриваются основные подходы к масштабированию баз данных, разрабатывается экспериментальный стенд на одной рабочей машине и проводится серия нагрузочных испытаний для нескольких конфигураций PostgreSQL. Практическая ценность работы заключается в получении наглядного и воспроизводимого сравнения двух подходов в условиях, доступных для учебного исследования.
2. Подходы масштабирования баз данных
В общем виде выделяют два основных подхода к масштабированию баз данных: вертикальное и горизонтальное.
2.1 Вертикальное масштабирование
Вертикальное масштабирование предполагает увеличение вычислительных ресурсов сервера, на котором размещена база данных. На практике это выражается в увеличении мощности процессора, объема оперативной памяти, пропускной способности накопителя и сетевых ресурсов. Данный подход позволяет повысить производительность без существенного изменения программной архитектуры и логики взаимодействия с базой данных.
К основным преимуществам вертикального масштабирования относятся простота внедрения, небольшие затраты на разработку и возможность быстрого повышения производительности системы.
Вместе с тем вертикальное масштабирование имеет ряд ограничений. Прежде всего, оно зависит от максимальных возможностей аппаратной платформы. По мере дальнейшего роста нагрузки наращивание ресурсов становится экономически менее выгодным. Кроме того, использование одного узла снижает отказоустойчивость системы.
2.2 Горизонтальное масштабирование
Горизонтальное масштабирование основано на распределении нагрузки между несколькими узлами. В отличие от вертикального подхода, здесь производительность повышается не за счет усиления одного сервера, а за счет добавления новых экземпляров базы данных или переноса части операций на отдельные узлы.
Одним из наиболее распространенных способов горизонтального масштабирования является использование read replica. В данной модели существует основной сервер базы данных, на который направляются операции записи, и один или несколько дополнительных серверов-реплик, предназначенных для обработки запросов чтения. Такой подход позволяет снизить нагрузку на основной сервер и повысить общую производительность системы в сценариях, где преобладают операции чтения.
Преимуществами горизонтального масштабирования являются гибкость, возможность распределения нагрузки и снижение времени отклика системы. При необходимости количество реплик может быть увеличено, что позволяет адаптировать систему к росту числа пользователей и запросов.
Однако горизонтальное масштабирование также сопровождается рядом сложностей. Оно требует более сложной конфигурации инфраструктуры, настройки репликации и изменения маршрутизации запросов. Кроме того, при использовании read replica существует риск отставания реплики от основного сервера, что может приводить к чтению неактуальных данных [4]. По этой причине такой подход подходит не для всех типов систем.
3. Эксперимент
3.1 Постановка эксперимента
В рамках исследования было выполнено сравнение трех конфигураций PostgreSQL: baseline – один экземпляр PostgreSQL без масштабирования; vertical – один экземпляр PostgreSQL с увеличенными вычислительными ресурсами; replica – конфигурация, включающая основной экземпляр PostgreSQL (primary) и реплику чтения (read replica).
Эксперимент проводился для двух сценариев нагрузки: readload – сценарий, ориентированный на операции чтения; mixedload – сценарий смешанной нагрузки (80% операций чтения и 20% записи). Измерения проводились на трех уровнях конкурентности: 20, 80 и 160 клиентов.
Для оценки эффективности конфигураций использовались показатели пропускной способности (TPS – количество транзакций, обрабатываемых за одну секунду) и задержки (latency) [5].
3.2 Результаты
В сценарии readload конфигурация replica показала наилучшие результаты на всех уровнях нагрузки. Конфигурация vertical также продемонстрировала значительный выигрыш по сравнению с baseline, однако во всех трех точках уступила конфигурации с репликой.
Таблица 1.
Сравнение конфигураций в сценарии readload
|
Число клиентов |
baseline TPS |
vertical TPS |
replica TPS |
baseline latency, мс |
vertical latency, мс |
replica latency, мс |
|
20 |
131106,165 |
277577,562 |
285208,195 |
0,152749 |
0,071740 |
0,070000 |
|
80 |
94082,634 |
214383,026 |
222623,051 |
0,850242 |
0,373239 |
0,359439 |
|
160 |
87977,624 |
200585,227 |
213296,427 |
1,818973 |
0,797746 |
0,750352 |
Из таблицы 1 видно, что переход от baseline к vertical практически удваивает пропускную способность системы, однако конфигурация replica обеспечивает еще более высокий результат.
По средней задержке наблюдается аналогичная картина, что также представлено на рисунке 1. Значение latency у baseline растет быстрее всего по мере увеличения числа клиентов, тогда как обе масштабируемые конфигурации обеспечивают существенно меньшие задержки. При этом replica на всех уровнях конкурентности показывает немного лучшие результаты, чем vertical.
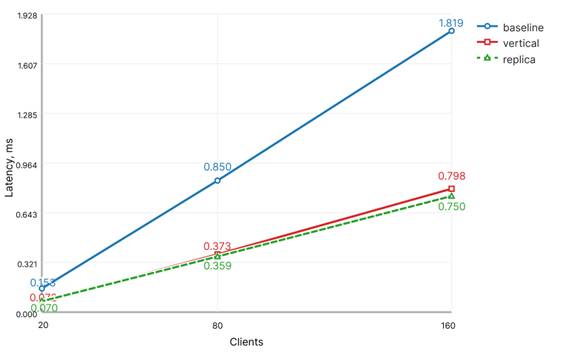
Рисунок 1. Задержка в сценарии readload
Таким образом, в сценарии readload горизонтальное масштабирование чтения оказалось более эффективным, чем простое увеличение ресурсов одного экземпляра базы данных.
В смешанном сценарии mixedload конфигурация replica также сохранила лидерство по общему TPS и средней задержке. Однако преимущество достигалось в первую очередь за счет операций чтения, тогда как по операциям записи конфигурация vertical оставалась сильнее.
Таблица 2.
Сравнение конфигураций в сценарии mixedload
|
Число клиентов |
baseline TPS |
vertical TPS |
replica TPS |
baseline latency, мс |
vertical latency, мс |
replica latency, мс |
|
20 |
113869,555 |
275539,317 |
280674,064 |
0,175637 |
0,072589 |
0,071381 |
|
80 |
88179,521 |
203546,882 |
212732,959 |
0,907340 |
0,392905 |
0,376215 |
|
160 |
80514,526 |
180025,680 |
189912,245 |
1,988513 |
0,888760 |
0,842475 |
Как видно из таблицы 2, конфигурация replica превосходит vertical по общему TPS на всех уровнях конкурентности.
Указанная тенденция подтверждается графиком общего TPS в смешанном сценарии (рис. 2), где конфигурация replica стабильно, хотя и умеренно, опережает vertical.
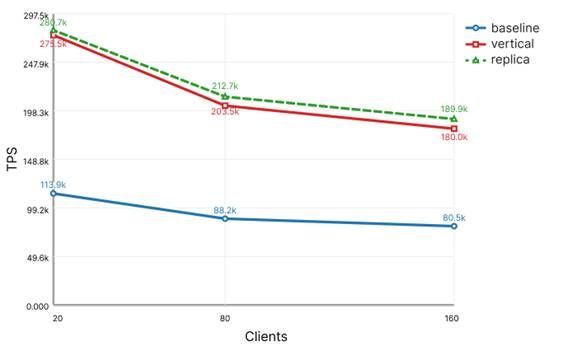
Рисунок 2. Общий TPS в сценарии mixedload
Однако для корректной интерпретации результатов смешанного сценария необходимо отдельно рассмотреть показатели операций чтения и записи.
Таблица 3.
Разделение mixed-сценария на чтение и запись
|
Число клиентов |
vertical read TPS |
replica read TPS |
vertical write TPS |
replica write TPS |
|
20 |
274742,747 |
280144,332 |
796,570 |
529,732 |
|
80 |
201974,673 |
211986,887 |
1572,208 |
746,073 |
|
160 |
178144,091 |
189203,700 |
1881,589 |
708,545 |
Данные таблицы 3 показывают, что преимущество конфигурации replica по общему TPS формируется главным образом за счет операций чтения. На всех уровнях нагрузки replica демонстрирует более высокий read TPS, чем vertical. В то же время по операциям записи вертикальная конфигурация заметно эффективнее.
На рисунке 3 показано, что по операциям чтения конфигурация replica стабильно превосходит vertical на всех рассмотренных уровнях конкурентности.
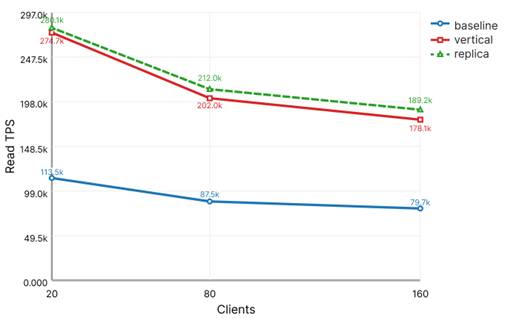
Рисунок 3. TPS операций чтения в сценарии mixedload
В то же время рисунок 4 демонстрирует обратную тенденцию для операций записи: по write TPS вертикальное масштабирование оказывается более эффективным.
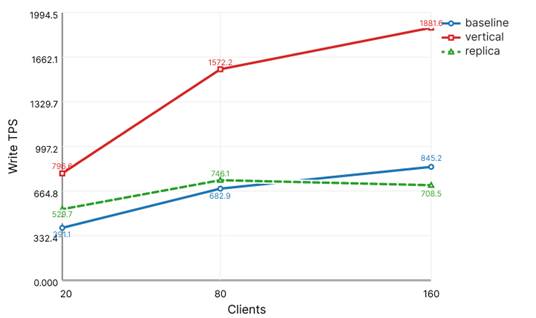
Рисунок 4. TPS операций записи в сценарии mixedload
Следовательно, для смешанной нагрузки с высокой долей чтения горизонтальное масштабирование чтения оказывается более эффективным по совокупным показателям, однако не заменяет вертикальное усиление в части нагрузки на запись.
Проведенное исследование показывает, что обе масштабируемые конфигурации существенно превосходят baseline по пропускной способности и средней задержке. Конфигурация vertical обеспечивает выраженный и устойчивый прирост производительности в обоих сценариях, однако конфигурация replica демонстрирует наилучшие результаты в тех случаях, когда значительная часть нагрузки приходится на чтение. В сценарии readload это преимущество проявляется наиболее явно: replica оказывается лучшей как по TPS, так и по latency. В сценарии mixedload конфигурация replica также лидирует по совокупной производительности, однако ее выигрыш обеспечивается главным образом за счет операций чтения, тогда как по операциям записи более эффективной остается конфигурация vertical. Таким образом, результаты эксперимента показывают, что горизонтальное масштабирование чтения наиболее целесообразно для систем с преобладанием операций чтения, тогда как вертикальное масштабирование сохраняет практическую значимость в условиях заметной нагрузки на запись.
4. Заключение
В работе был проведен сравнительный анализ подходов к масштабированию СУБД PostgreSQL в условиях роста нагрузки на систему. В ходе исследования были рассмотрены основные теоретические положения, разработан экспериментальный стенд и выполнена серия нагрузочных испытаний для нескольких конфигураций базы данных.
Результаты исследования показали, что применение масштабирования позволяет существенно повысить производительность системы по сравнению с базовой конфигурацией. Вместе с тем эффективность конкретного подхода определяется характером нагрузки, особенностями архитектуры и практическими требованиями к системе.
Таким образом, поставленная цель работы была достигнута. Проведенное исследование показало практическую значимость сравнительного анализа подходов к масштабированию PostgreSQL и подтвердило, что даже в учебных условиях возможно получить наглядные результаты, позволяющие оценить применимость различных архитектурных решений.
Список литературы:
1. What Is PostgreSQL? [Электронный ресурс] – Режим доступа. – URL: https://www.postgresql.org/docs/current/intro-whatis.html (Дата обращения 20.03.2026).
2. Cloud scalability: When should you scale-up vs. scale-out? [Электронный ресурс] – Режим доступа. – URL: https://www.ibm.com/think/topics/scale-up-vs-scale-out (Дата обращения 02.04.2026).
3. Working with read replicas for Amazon RDS for PostgreSQL [Электронный ресурс] – Режим доступа. – URL: https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_PostgreSQL.Replication.ReadReplicas.html (Дата обращения 02.04.2026).
4. Read replicas – Azure Database for PostgreSQL [Электронный ресурс] – Режим доступа. – URL: https://learn.microsoft.com/en-us/azure/postgresql/read-replica/concepts-read-replicas (Дата обращения 02.04.2026).
5. pgbench [Электронный ресурс] – Режим доступа. – URL: https://www.postgresql.org/docs/current/pgbench.html (Дата обращения 04.04.2026).
