Статья:




Исследование моделей хостинга: имитационное моделирование
Секция: Технические науки
Выходные данные
Измайлов Р.Ю. Исследование моделей хостинга: имитационное моделирование // Молодежный научный форум: Технические и математические науки: электр. сб. ст. по мат. XLI междунар. студ. науч.-практ. конф. № 1(41). URL: https://nauchforum.ru/archive/MNF_tech/1(41).pdf (дата обращения: 01.08.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 0 голосов
Мне нравится0
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

XLI Студенческая международная заочная научно-практическая конференция «Молодежный научный форум: технические и математические науки»
Исследование моделей хостинга: имитационное моделирование
Измайлов Рамазан Юнус оглы
студент, Севастопольский государственный университет СевГУ, РФ, г.Севастополь
Мащенко Елена Николаевна
научный руководитель, доц., Севастопольский государственный университет, СевГУ, РФ, г.Севастополь
В связи с ростом требований к качеству и доступности веб-сервисов жестко встает вопрос об оптимальном выборе модели хостинга для развертывания веб-сервисов. Существует три наиболее распространенные модели хостинга: выделенный сервер, виртуальный сервер, облачный сервер [1, с. 2]. Поэтому является актуальной задача разработки имитационной модели, позволяющей учитывать ключевые особенности моделей хостинга.
Модель должна учитывать следующие параметры:
· производительность серверов;
· ценовая политика;
· сложность развертывания;
· вероятность отказа серверов;
· скорость восстановления серверов.
С помощью имитационной модели необходимо получить и сравнить следующие характеристики функционирования серверов:
· средняя загрузка серверов;
· среднее содержимого входного буфера;
· вероятность обработки запроса сервером.
Концептуальное описание модели.
Необходимо провести синтез и анализ структуры модели S, реализующей следующее преобразование (1).
Y = S(DH, VH, CH, P), (1)
где: Y – кортеж получаемых характеристик, S – реализуемая структура, DH – кортеж параметров, описывающих модель хостинга «Выделенный сервер», VH – кортеж параметров, описывающих модель хостинга «Виртуальный сервер», CH – кортеж параметров, описывающих модель хостинга «Облачный сервер», P – параметры закона распределения интервалов между появлениями заявок и трудоемкости обработки запроса.
Причем, кортеж Y состоит из элементов:
· y11 – средняя загрузка выделенного сервера;
· y12 – среднее содержимого входного буфера;
· y13 – вероятность обработки заявки выделенным сервером;
· y21 – средняя загрузка виртуального сервера;
· y22 – среднее содержимого входного буфера;
· y23 – вероятность обработки заявки виртуальным сервером сервером;
· y31 – средняя загрузка облачного сервера;
· y32 – среднее содержимого входного буфера;
· y33 – вероятность обработки заявки облачным сервером.
Кортеж DH содержит элементы:
· d11 – (характеристика сервера), количество операций в секунду;
· d12 – среднее время между отказами;
· d13 – среднеквадратичное отклонение времени между отказами от среднего;
· d14 – емкость входного буфера.
Кортеж VH содержит элементы:
· v11 – (характеристика сервера), количество операций в секунду;
· v12 – среднее время между отказами;
· v13 – среднеквадратичное отклонение времени между отказами от среднего;
· v14 – емкость входного буфера.
Кортеж CH содержит элементы:
· c11 – (характеристика сервера), количество операций в секунду;
· c12 – среднее время между отказами;
· c13 – среднеквадратичное отклонение времени между отказами от среднего;
· c14 – емкость входного буфера.
Кортеж P содержит элементы:
· p1 – математическое ожидание времени между появлениями запросов;
· p2 – среднеквадратичное отклонение времен между появлениями заявок;
· p3 – математическое ожидание операций в секунду для обработки запроса;
· p4 – среднеквадратичное отклонение операций в секунду для обработки запроса.
В качестве критерия оценки эффективности работы системы выбраны следующие параметры: загрузка серверов, вероятность обработки заявки сервером, средняя длина очереди во входном буфере. Независимые переменные модели:
· y11 – средняя загрузка выделенного сервера;
· y12 – среднее содержимого входного буфера;
· y13 – вероятность обработки заявки выделенным сервером;
· y21 – средняя загрузка виртуального сервера;
· y22 – среднее содержимого входного буфера;
· y23 – вероятность обработки заявки виртуальным сервером сервером;
· y31 – средняя загрузка облачного сервера;
· y32 – среднее содержимого входного буфера;
· y33 – вероятность обработки заявки облачным сервером.
Зависимые переменные модели:
· загрузка серверов;
· вероятность обработки заявки сервером;
· средняя длина очереди во входном буфере.
Кроме того, для более точного построения модели была разработана диаграмма потоков данных (Data Flow Diagram, DFD) [3, с. 132]. Так называется методология графического структурного анализа, описывающая внешние по отношению к системе источники и адресаты данных, логические функции, потоки данных и хранилища данных, к которым осуществляется доступ. Диаграмма была разработана с помощью программы Visual Paradigm. [4]. Продукт позволяет разрабатывать различные диаграммы, DFD – в том числе. Диаграмма приведена на рисунке 1.
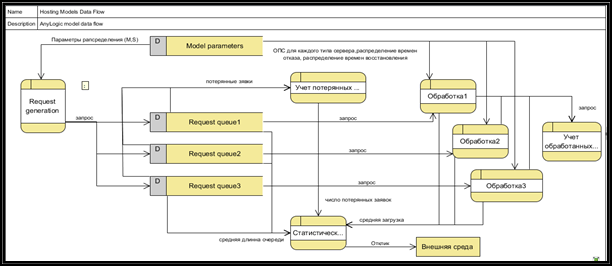
Рисунок 1. Диаграмма потоков данных имитационной модели
Перспективы дальнейших исследований. В дальнейшем предполагается реализация модели в среде имитационного моделирования AnyLogic [5]. Кроме того, будут проведены полный факторный эксперимент и отсеивающий эксперимент. Полным факторным экспериментом (ПФЭ) называется эксперимент, реализующий все возможные не повторяющиеся комбинации независимых переменных, каждая из которых принудительно варьируется на двух уровнях. Число этих комбинаций N = 2n определяет тип планирования [2, c. 108]. Отсеивающие эксперименты позволяют исключить незначительные факторы в начальной стадии экспериментального исследования и тем самым упростить описание поверхности отклика и сократить общий объем экспериментальных работ [2, с. 37]. По результатам экспериментов будет проведено исследование характеристик качества моделей хостинга.
Список литературы:
1. Измайлов Р.Ю. Сравнительный анализ моделей хостинга для развертывания веб-приложений // Молодежный научный форум: Технические и математические науки: электр. сб. ст. по материалам XXXVII студ. междунар. заочной науч.-практ. конф. – М.: «МЦНО». – 2016 – № 8(37) / – [Электронный ресурс] – Режим доступа. – URL: http://nauchforum.ru/archive/MNF_social/8(37).pdf.
2. Сидняев Н.И. Теория планирования эксперимента и анализ статистических данных. / Н.И. Сидняев – М.: Юрайт-Издат, ООО, 2012. – 399с.
3. Томашевский В.М. Моделирование систем / В.М. Томашевский. – Киев: Издательская группа BHV, 2005. – 352 с.
4. Электронный ресурс: https://www.visual-paradigm.com.
5. Электронный ресурс: http://www.anylogic.ru.
