ОЦЕНКА ПОТЕНЦИАЛА ТОРГОВОЙ ЛОКАЦИИ НА ОСНОВЕ ГЕОПРОСТРАНСТВЕННЫХ ДАННЫХ И АНСАМБЛЕВЫХ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ
Конференция: CVI Международная научно-практическая конференция «Научный форум: экономика и менеджмент»
Секция: Математические и инструментальные методы экономики

CVI Международная научно-практическая конференция «Научный форум: экономика и менеджмент»

ОЦЕНКА ПОТЕНЦИАЛА ТОРГОВОЙ ЛОКАЦИИ НА ОСНОВЕ ГЕОПРОСТРАНСТВЕННЫХ ДАННЫХ И АНСАМБЛЕВЫХ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ
ASSESSING THE POTENTIAL OF A RETAIL LOCATION BASED ON GEOSPATIAL DATA AND ENSEMBLE MACHINE LEARNING METHODS
Baidin Pavel Igorevich
Postgraduate Student, Department of Information Systems and Information Security, St. Petersburg State University of Industrial Technologies and Design, Russia, Saint Petersburg
Аннотация. В статье описан прикладной подход к оценке потенциала торговой локации: от выбора пространственных данных до формирования признаков и запуска ансамблевых моделей машинного обучения. Потенциал локации рассматривается как сочетание пяти компонентов: локального спроса, транспортной доступности, конкурентной среды, инфраструктурного окружения и цифровых характеристик точки. Показано, что перевод этих компонентов в числовые признаки позволяет получить воспроизводимую оценку локации.
Abstract. This article describes an applied approach to identifying retail location opportunities: from selecting spatial data to formulating criteria and running multiple machine learning models. Potential locations are the result of a combination of five components: local lighting, transportation accessibility, competitive environment, infrastructure surroundings, and digital feature points. It is shown that translating these components into numerical features allows for the creation of reproducible sensor locations.
Ключевые слова: геопространственные данные, торговая локация, машинное обучение, признаки модели, H3, XGBoost, розничная торговля.
Keywords: geospatial data, retail location, machine learning, model features, H3, XGBoost, retail.
Введение
Оценка торговой локации является важной задачей розничного бизнеса, поскольку коммерческий результат точки зависит не только от ассортимента и цен, но и от характеристик места. На выручку влияют плотность населения, трафик, транспортная доступность, конкуренты и объекты городской инфраструктуры.
Современная геоаналитика позволяет перейти от экспертной оценки места к количественной модели. Пространственные данные могут быть преобразованы в набор признаков, а затем использованы для прогнозирования выручки, объема продаж или рейтинга привлекательности локации [7].
Цель статьи - показать краткую прикладную схему: какие пространственные данные можно использовать, как превратить их в признаки модели и какие алгоритмы машинного обучения можно запустить для оценки потенциала локации.
Пространственные данные для модели
Пространственные данные - это сведения, связанные с координатами или территорией. Для оценки торговой локации они описывают окружение точки продаж: кто живет рядом, насколько место доступно, какие конкуренты и инфраструктурные объекты находятся поблизости.
В данной статье потенциал торговой локации понимается как интегральная характеристика места, которая показывает ожидаемую способность точки привлекать спрос и обеспечивать продажи. Для практической модели его удобно разложить на пять компонентов: локальный спрос, транспортная доступность, конкурентная среда, инфраструктурное окружение и цифровая представленность точки.
Для отдельных видов бизнеса набор пространственных факторов должен уточняться. Например, для цветочного ритейла важны не только жилой фонд и пешеходный поток, но и близость ЗАГСов, ресторанов, больниц, школ, бизнес-центров и других объектов, формирующих событийный спрос.
Таблица 1.
Компоненты потенциала локации и признаки модели
|
Компонент потенциала |
Пространственные данные |
Признаки модели |
Ожидаемый эффект |
|
Локальный спрос |
население, квартиры, доходы домохозяйств |
число квартир в радиусе 500 м; средний доход; емкость зоны |
оценивает базовый платежеспособный спрос |
|
Транспортная доступность |
пешеходный и автомобильный трафик, метро, остановки |
трафик в месяц; расстояние до метро и ОТ; транзитный индекс |
показывает вероятность импульсной покупки |
|
Конкурентная среда |
магазины той же ктегории и их удаленность |
число конкурентов; расстояние до ближайшего конкурента; индекс конкурентного давления |
учитывает перераспределение спроса между точками |
|
Инфраструктурное окружение |
ЗАГСы, рестораны, больницы, школы, БЦ и другие POI |
расстояния до POI; событийный, социальный и ритуальный индексы |
выявляет генераторы тематического и событийного спроса |
|
Цифровые характеристики точки |
рейтинг, отзывы, возраст точки, сетевой статус |
средняя оценка; число отзывов; возраст; размер сети |
дополняет оценку устойчивостью и узнаваемостью точки |
Связь между компонентами потенциала и признаками модели принципиальна: модель оценивает не саму карту, а числовое описание факторов, которые могут усиливать или ослаблять спрос. Например, высокий пешеходный трафик повышает вероятность случайной покупки, близость ЗАГСа или ресторана отражает событийный спрос, а большое число конкурентов может снижать удельный потенциал зоны.
Преобразование данных в признаки
Модель машинного обучения не работает с картой напрямую. Для обучения требуется таблица, где каждая строка соответствует торговой точке или пространственной ячейке, а столбцы содержат числовые признаки. Поэтому основной этап подготовки данных - перевод пространственной информации в измеримые переменные.
На первом шаге выполняется пространственная привязка: точка получает координаты и связывается с единицей анализа. Такой единицей может быть буфер вокруг магазина, изохрона пешей доступности, административная зона или гексагональная ячейка H3. Гексагональная сетка удобна тем, что позволяет сравнивать территории одинакового масштаба и агрегировать показатели городской среды.
На втором шаге рассчитываются базовые признаки: расстояние до ближайших объектов, количество объектов в радиусе, наличие объекта в зоне доступности, объем трафика, число конкурентов, плотность жилой застройки. Например, для модели можно рассчитать количество магазинов-конкурентов в радиусе 500 м и расстояние до ближайшей станции метро.
На третьем шаге формируются производные индексы. Емкость торговой зоны может быть рассчитана как произведение количества квартир на средний доход домохозяйств, а удельный потенциал - как отношение емкости спроса к числу конкурентов. Также можно рассчитывать индексы близости к инфраструктурным объектам, где вклад объекта уменьшается по мере роста расстояния.
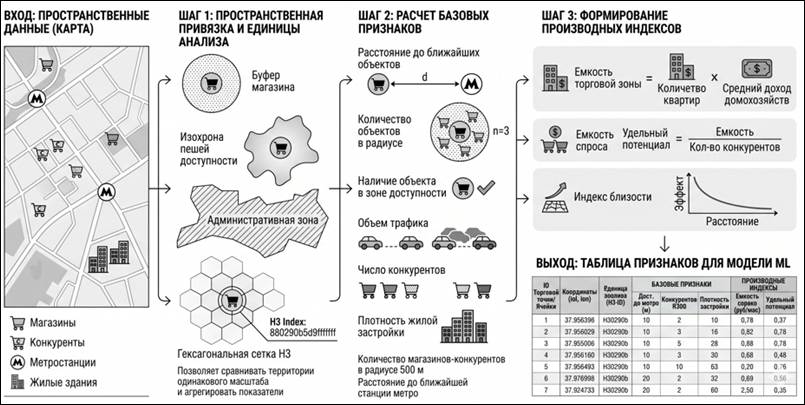
Рисунок 1. Схема преобразования пространственных данных в признаки модели
Таким образом, исходная карта превращается в признаковое пространство, пригодное для машинного обучения: координаты и объекты городской среды становятся расстояниями, счетчиками, индексами и показателями доступности.
Модели и пример результата
После формирования признаков задача оценки потенциала локации может быть поставлена как задача регрессии. Целевой переменной выступает выручка, объем продаж или иной показатель эффективности. В качестве базовой модели используется линейная регрессия, а для учета нелинейных связей - ансамблевые методы: Random Forest, CatBoost и XGBoost.
Ансамблевые алгоритмы подходят для такой задачи, поскольку работают с разнородными табличными признаками и позволяют учитывать взаимодействие факторов. Например, близость метро может быть значимой только при высоком пешеходном трафике, а большое число конкурентов может одновременно указывать и на давление конкуренции, и на сформированную торговую зону [3; 6; 8].
В качестве примера были обучены модели для прогнозирования среднемесячной выручки и объема продаж торговых точек цветочного ритейла. Качество сравнивалось по процентной ошибке на тестовой выборке.
Таблица 2.
Сравнение моделей по тестовой ошибке прогноза
|
Модель |
Выручка, % |
Продажи, % |
Вывод |
|
XGBoost |
17,33 |
18,14 |
Лучший результат |
|
CatBoost |
18,70 |
19,76 |
Близкое качество |
|
Random Forest |
17,91 |
19,52 |
Устойчивый ансамбль |
|
Decision Tree |
24,19 |
23,49 |
Хуже ансамблей |
|
Linear Regression |
27,45 |
27,60 |
Слабая базовая модель |
Полученные результаты показывают, что ансамблевые модели заметно превосходят линейную регрессию. Наилучшее качество показал XGBoost: ошибка составила 17,33% по выручке и 18,14% по объему продаж. По сравнению с линейной регрессией ошибка прогноза выручки снижается примерно на треть. Иными словами, эффект подхода состоит в том, что пространственные данные после преобразования в признаки становятся измеримыми факторами модели и позволяют получить более точную оценку локации, чем простая линейная зависимость.
Практическая ценность подхода заключается в том, что предприниматель или аналитик может сравнить несколько потенциальных мест до открытия точки. Итоговый прогноз следует рассматривать вместе с арендной ставкой, площадью помещения, форматом бизнеса и другими управленческими ограничениями.
Заключение
Геопространственные данные позволяют формализовать оценку торговой локации и превратить ее в воспроизводимую аналитическую задачу. Потенциал локации может быть представлен через пять компонентов: локальный спрос, транспортную доступность, конкурентную среду, инфраструктурное окружение и цифровые характеристики точки. Каждый компонент переводится в набор признаков: расстояния, счетчики объектов, показатели трафика, индексы емкости и конкурентного давления.
Для оценки потенциала локации целесообразно использовать ансамблевые методы машинного обучения, поскольку они учитывают нелинейные зависимости между факторами городской среды и коммерческими показателями торговой точки. Предложенная схема может применяться к разным форматам розничной торговли при условии адаптации набора пространственных признаков к специфике отрасли.
