Разработка программного комплекса для быстрого поиска, обработки и хранения больших объемов данных
Конференция: XLIII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»
Секция: Информатика, вычислительная техника и управление

XLIII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»

Разработка программного комплекса для быстрого поиска, обработки и хранения больших объемов данных
Аннотация. Данная статья посвящена разработке программы для быстрой обработки и поиска и больших объемов данных. В статье разработана программа для быстрого поиска и обработки информации на языке программирования С++. Данная программа призваны усовершенствовать методы обработки и поиска информации на предприятиях.
Ключевые слова: большие данные; информация; программа; язык программирования; среда разработки.
Введение
Большие данные (Big data) — это разнообразные данные, которые поступают с постоянно растущей скоростью и объем которых постоянно растет. Хотя термин «большие данные» является относительно новым, процесс сбора и хранения больших объемов информации имеет давнюю историю [1]. Концепцию определения больших данных можно сформулировать как совокупность следующих факторов: Volume, Variety, Velocity и Value, — объем, вариативность, скорость и ценность.
Большие данные отличаются своими количественными характеристиками. Возрастающее количество информации, создаваемых как людьми, так и машинами, предъявляет к IT инфраструктуре новые требования в отношении хранения, обработки данных и предоставления доступа [2].Большие объемы данных является серьезной проблемой для средств обработки и поиска информации [3].В связи с этим разработка новых методов и алгоритмов анализа, больших и сверхбольших коллекций данных становятся все более актуальной и необходимой задачей.
Поэтому проблема больших данных, применяемых в разных прикладных областях требуют новых разработок, направленных на создание масштабируемых программных решений.
Задачами данной статьи являются:
1)Выбор среды разработки и языка программирования;
2)Разработка программы на разных языках программирования для поиска информации в файлах с большим объемом данных. Программа должна удовлетворять следующим требованиям:
- Иметь интуитивно понятный интерфейс;
- Работать с файлами любого формата;
- Выполнять поиск любых значений в файлах;
- Загружать информацию из
- файла размером 1 ГБ менее чем за 5 минут;
3)Тестирование разработанной программы;
1. Выбор языка программирования, среды разработки программ для загрузки файлов.
1.1. Общая схема работы
Основной алгоритм программы показан на рис.1. Он выглядит следующим образом. Пользователь запускает программу и открывает нужный файл. Этот файл сохраняется в буфере обмена программы. Дальше в текстовом поле вводится значение, которое нужно найти в текстовом файле. Программа ищет все строки, в которых присутствует данное значение и выводит их на консоль.

Рисунок 1. Схема работы программы
1.2. Реализация программы
Для реализации программы также выбрана среда программирования Microsoft Visual Studio. Для программы будет использована библиотека QT.
Qt — кроссплатформенная библиотека разработки GUI на С++. Библиотека Qt является объектно-ориентированной, базирующейся на компонентах и имеет богатое разнообразие различных визуальных элементов – виджетов [4].
Язык программирования С++ компилируемый строго типизированный язык программирования общего назначения, который подходит для создания самых различных приложений [5].
На главной форме программы представленной на рис.3присутствуют следующие элементы:
- QPushButton - командная кнопка;
- QLineEdit – это редактор однострочного текста;
- QTextEdit - позволяет редактировать многострочный форматированный текст;
Реализация программы на языке C++ выглядит следующим образом (приведена только основная часть кода):

Рисунок 2. Программный код
Интерфейс программы
Рисунок 3. Главная форма «Программы 2»
2.Тестирование программы
Возьмем файл размером лог-файл размером 1,22 ГБ. Далее вводим значение для поиска в текстовом поле «9952».
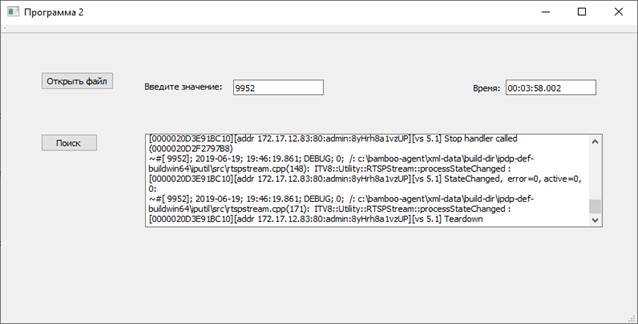
Рисунок 4. Результат работы «Программы 1»
Программа как видно на рис.4 загрузила данные из файла за 00:03:58.002. Данные были загружены менее чем за 5 минут и, следовательно программа, уложилась во временной лимит.
В результате работы была создана программа для быстрого поиска и выгрузки данных. Программа была написана на языке С++.
Практическая значимость результатов состоит в том, что разработанная программа, позволят усовершенствовать методы обработки и поиска больших данных.
