СРАВНЕНИЕ БИБЛИОТЕК ГЛУБОКОГО МАШИННОГО ОБУЧЕНИЯ НА CIFAR-10
Журнал: Научный журнал «Студенческий форум» выпуск №15(238)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №15(238)
СРАВНЕНИЕ БИБЛИОТЕК ГЛУБОКОГО МАШИННОГО ОБУЧЕНИЯ НА CIFAR-10
COMPARISON OF DEEP LEARNING LIBRARIES ON CIFAR-10 DATASET
Almaz Fashutdinov
Student of magistracy Information systems and technologies FSBEI of HE Kazan National Research Technological University, Russia, Kazan
Аннотация. Глубокое обучение стало очень популярным в последние годы. Большой прогресс был достигнут в задаче классификации образов (изображений) с развитием глубокого обучения. Данная задача обширно применяется во многих сферах. В данной статье мы познакомимся со следующими библиотеками машинного обучения: TensorFlow, PyTorch, MXNet, проведем анализ (эксперимент) на основе набора данных CIFAR-10 выясним, какая из библиотек будет наиболее эффективна.
Abstract. In recent years, Deep Learning has become very popular. Significant progress has been made in image classification tasks with the development of Deep Learning. This task is extensively used in many fields. In this article, we will introduce the following Machine Learning libraries: TensorFlow, PyTorch, MXNet, and conduct an analysis (experiment) based on the CIFAR-10 dataset to determine which library will be the most efficient.
Ключевые слова: классификация изображений, распознавание образов, нейронная сеть, машинное обучение, TensorFlow, PyTorch, MXNet.
Keywords: image classification, pattern recognition, neural network, Machine Learning, TensorFlow, PyTorch, MXNet.
Машинное обучение стало ключевым фактором прогресса во многих областях благодаря расширенной использованию сложных моделей и объемных наборов данных. Кроме того, появились новые инструменты и программы для упрощения процесса обучения моделей. Сегодня особенно востребована задача классификации изображений, которая используется в системах автоматического наблюдения, робототехнике и машиностроении. Хотя глубокое обучение уже представлено в математическом виде, его необходимо преобразовать в компьютерный язык, что делают различные библиотеки и фреймворки машинного обучения.[1]
На рынке современных технологий доступно множество библиотек для машинного обучения. Есть как уже зарекомендовавшие себя библиотеки, так и более свежие [2]. Также на рынке представлено множество разнообразных библиотек для построения нейронных сетей, включая популярную open source платформу TensorFlow. TensorFlow была изначально разработана для языка Python, но теперь поддерживает работу на многих других языках.[2] (см. таблицу 1).
Рисунок 1. Временная шкала появления фреймворков
Алгоритмы машинного обучения в TensorFlow - это выполнение математических операций в форме ориентированного графа, где вершины и узлы производят определенные действия, а ребра передают данные. Данные представлены в виде многомерных массивов (тензоров) переменной длины. Узлы функционируют параллельно и асинхронно, когда все тензоры из входных ребер становятся доступными. TensorFlow - это эффективный и легко расширяемый фреймворк для глубокого обучения, благодаря чему имеет большое количество руководств и документации, а также обширное комьюнити. [3].
Процесс создания модели и ее последующего обучения можно представить в виде схемы, которая представлена ниже [4].

Рисунок 2. Рабочий процесс TensorFlow
PyTorch - это фреймворк для машинного обучения, который был создан компанией Facebook (социальная сеть, запрещенная на территории РФ, как продукт организации Meta, признанной экстремистской – прим.ред.)
) на языке Python и имеет открытый исходный код. Он использует PyTorch тензоры для представления данных, которые являются многомерными матрицами, изменяемыми для обучения и тестирования сети. PyTorch использует динамические вычисления, что обеспечивает большую гибкость для построения сложных архитектур. Недостаток заключается в том, что меньше учебных примеров и сообщество менее многочисленно по сравнению, например, с TensorFlow. [5].
На рисунке ниже описана базовая цепочка действий для проекта на PyTorch вместе с важными модулями и соответствующими им методами, которые используются на каждом шаге создания и обучения модели.
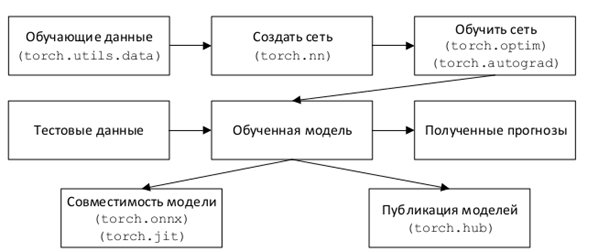
Рисунок 3. Рабочий процесс PyTorch
MXNet – платформа глубокого обучения с открытым исходным кодом была разработана совместными усилиями Университета Карнеги-Меллона, Вашингтонским университетом и Microsoft [6]. Фреймворк быстрый, гибкий, легко масштабируем, позволяет обучать глубокие нейронные сети с использованием различных языков программирования (см. таблицу 1).
Недостатки MXNet схожи с PyTorch: платформа не так популярна в научном сообществе, поэтому стоит учитывать возможность не получить быстрый отклик в решении какой-либо проблемы [7].
Ниже представлена схема системной архитектуры MXNet. На ней отображены основные модули и компоненты системы и их взаимодействие.

Рисунок 4. Системная архитектура MXNet
Систему можно разделить на две большие части: модули интерфейса пользователя (верхняя часть схемы) и системные модули (нижняя часть схемы). В таблице 1 собраны основные свойства рассмотренных выше библиотек.
Таблица 1.
Основные свойства библиотек глубокого обучения.
|
|
TensorFlow |
PyTorch |
MXNet |
|
Дата выхода |
2015 |
2017 |
2015 |
|
Язык реализации |
Python, C++ |
Python, C++ |
Python, C++ |
|
Платформа |
macOS, Windows, Linux, Android, iOS |
Linux, macOS, Windows |
Windows, macOS, Linux |
|
Поддерживаемые языки |
Python, C++, Java, Go, R, Julia, C#, JavaScript, Swift, Haskell, Rust |
Python, C++ |
C++, Python, Julia, Matlab, JavaScript, Go, R, Scala, Perl, Java |
|
Отказоустойчивос ть |
Контрольная точка и восстановление |
Контрольная точка и возобновление |
Контрольная точка и возобновление |
|
Параллельные вычисления |
Да |
Да |
Да |
|
Последняя версия |
2.4.1 (21 января 2021) |
1.8.0 (4 марта 2021) |
1.8.0 (3 марта 2021) |
|
Лицензия |
Apache License 2.0 |
BSD |
Apache License 2.0 |
|
Популярность (звезды на GitHub) |
155к |
47,7к |
19,4к |
Практически все библиотеки имеют схожие характеристики, за исключением PyTorch, который ограничен в поддержке языков программирования. Мы проведем эксперимент на наборе данных CIFAR-10, который состоит из 60000 цветных изображений, разделенных на десять классов и пять обучающих пакетов, а также один тестовый пакет. Изображения в пакетах для обучения представлены в случайном порядке. [8]. Из-за низкого разрешения (32x32) изображений в этом датасете, исследователи могут быстро проверить различные алгоритмы. Обучение было проведено и изображения были распознаны с помощью всех трех фреймворков. [9]. Ниже представлена диаграмма времени обучения моделей.
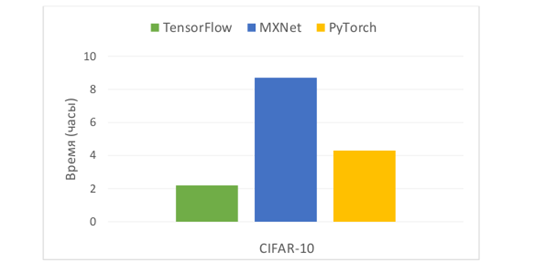
Рисунок 5. Время обучения
Следующая диаграмма отображает точность распознавания изображений каждой из обученных моделей.

Рисунок 6. Результаты эксперимента
В проведенном эксперименте было заметно, что использование библиотеки TensorFlow приводит к лучшим результатам обучения, занимая всего 2,2 часа вместо 4,3 и 8,7 часов, а также показав наибольшую точность распознавания на наборе данных CIFAR-10 - 82%. В сравнении с MXNet и PyTorch, TensorFlow является лучшим выбором для большинства проектов, так как предоставляет более высокоуровневые оболочки, такие как Keras и Sonnet, что значительно облегчает использование библиотеки. Более того, TensorFlow находит применение в многих областях.
