РАЗРАБОТКА И ОЦЕНКА КАЧЕСТВА СИСТЕМЫ РАСПОЗНАВАНИЯ ЗВУКА ВЫСТРЕЛА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ
Журнал: Научный журнал «Студенческий форум» выпуск №41(308)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №41(308)
РАЗРАБОТКА И ОЦЕНКА КАЧЕСТВА СИСТЕМЫ РАСПОЗНАВАНИЯ ЗВУКА ВЫСТРЕЛА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ
DEVELOPMENT AND EVALUATION OF THE QUALITY OF A SHOT SOUND RECOGNITION SYSTEM USING MACHINE LEARNING ALGORITHMS
Danilin Ilia
Student, Bauman Moscow State Technical University, Russia, Moscow
Leontev Igor
Student, Bauman Moscow State Technical University, Russia, Moscow
Anastasia Kadyrbaeva
Scientific supervisor, assistant, Bauman Moscow State Technical University, Russia, Moscow
Vyacheslav Nedashkovsky
Scientific supervisor, Candidate of Technical Science, associate professor, Bauman Moscow State Technical University, Russia, Moscow
Аннотация. На сегодняшний день крайне актуальной является разработка систем распознавания звука выстрела. В ходе разработки таких систем возникают следующие задачи: выбор признаков и формирование тренировочного и тестового датасетов, выбор и обучение модели, проверка точности модели. В статье представлены алгоритмы, решающие данные задачи с помощью функционала среды вычислений MATLAB, а так же приведена оценка точности получившейся системы при различных уровнях зашумления входных данных.
Abstract. Today, the development of gunshot sound recognition systems is extremely relevant. During the development of such systems, the following tasks arise: the selection of features and the formation of training and test datasets, the selection and training of the model, checking the accuracy of the model. The article presents algorithms that solve these problems using the MATLAB computing environment functionality, and also provides an estimate of the accuracy of the resulting system at various levels of input noise.
Ключевые слова: машинное обучение; обработка звука; распознавание звука выстрела; модель случайного леса; MATLAB.
Keywords: machine learning; sound processing; gunshot sound recognition; random forest model; MATLAB.
Введение. В условиях современного мира, где уровень преступности и террористических угроз остается высоким [1, c. 45], разработка эффективных систем безопасности становится критически важной. Автоматическое распознавание звука выстрела может значительно повысить оперативность реагирования правоохранительных органов и спасательных служб, что, в свою очередь, способствует снижению уровня преступности и улучшению общественной безопасности.
Современные технологии обработки звуковых сигналов и машинного обучения предоставляют новые возможности для создания высокоэффективных систем классификации звуковых событий. Разработка таких систем требует глубокого понимания акустических характеристик звуков выстрелов, а также применения передовых методов анализа данных и алгоритмов машинного обучения. Интеграция таких систем в существующие инфраструктуры безопасности, такие как камеры наблюдения и системы оповещения, может значительно повысить их эффективность. Это позволяет создать комплексные решения, которые обеспечивают всестороннюю защиту и мониторинг общественных пространств, что особенно актуально для крупных городов и мероприятий с большим скоплением людей.
Разработка и внедрение таких систем способствует развитию науки и техники в области акустики, обработки сигналов и искусственного интеллекта. Это открывает новые перспективы для научных исследований и инноваций, что, в свою очередь, может привести к созданию новых технологий и решений в других областях
Таким образом, разработка и оценка качества системы распознавания звука выстрела с использованием алгоритмов машинного обучения является актуальной и перспективной темой, как с точки зрения обеспечения общественной безопасности, так и с точки зрения научно-технического прогресса.
Целью данной работы является разработка системы, способной при поступлении на вход аудиофайла определить наличие выстрела с известной точностью.
Для выполнения поставленной цели решаются следующие задачи:
- Выбор признаков и написание алгоритма формирования тренировочного и тестового датасета.
- Выбор и обучение модели.
- Написание алгоритма проверки точности модели и оценить точность модели при различном зашумлении входных данных.
В качестве среды разработки была выбрана MATLAB, по причине наличия большого количества встроенных инструментов для обработки и визуализации данных.
Материалы и методы решения задач, принятые допущения. В данной главе приведено краткое описание признаков, используемых для классификации звука выстрела, некоторые сведения о алгоритме машинного обучения случайный лес. Описано применение низкочастотного фильтра и нормализации громкости перед извлечением признаков. Приняты допущения.
Признаки аудиоданных. Для тренировки модели были выбраны следующие признаки аудиоданных:
Среднее значение аудиоданных: Этот признак представляет собой среднее арифметическое всех значений аудиосигнала. Он полезен для определения общего уровня громкости сигнала.
Стандартное отклонение аудиоданных: Стандартное отклонение показывает, насколько значения аудиосигнала отклоняются от среднего значения. Этот признак важен для оценки вариабельности сигнала.
Дисперсия аудиоданных: Дисперсия является квадратом стандартного отклонения и также используется для оценки вариабельности сигнала.
Среднее значение абсолютных разностей между соседними отсчетами: Этот признак помогает оценить, насколько быстро изменяется сигнал, что важно для распознавания резких звуков, таких как выстрелы.
Сумма квадратов аудиоданных: Этот признак используется для оценки энергии сигнала и может быть полезен для выявления высокоэнергетических событий.
Эксцесс аудиоданных: Эксцесс (или коэффициент эксцесса) показывает, насколько распределение значений сигнала отличается от нормального распределения. Это важно для оценки формы распределения сигнала.
Асимметрия аудиоданных: Асимметрия (или коэффициент асимметрии) показывает, насколько распределение значений сигнала отклоняется от симметричного распределения. Этот признак важен для оценки асимметрии сигнала.
Мел-частотные кепстральные коэффициенты (MFCC): MFCC являются одними из наиболее широко используемых признаков в аудиоанализе. Они представляют собой набор коэффициентов, которые описывают спектральные характеристики сигнала. MFCC были выбраны для тренировки алгоритма случайного леса, так как они эффективно представляют частотные характеристики звука и позволяют различать различные звуковые события [2].
Алгоритм машинного обучения "Случайный лес" и его применение в распознавании звуковых событий. Алгоритм "Случайный лес" (Random Forest) является одним из наиболее популярных и эффективных методов машинного обучения, особенно в задачах классификации и регрессии [3]. Он представляет собой ансамбль деревьев решений, где каждое дерево обучается на случайной подвыборке данных и признаков. Это позволяет уменьшить переобучение и улучшить общую точность модели.
Применение случайного леса в распознавании звуковых событий, таких как звук выстрела, обусловлено его способностью обрабатывать большие объемы данных и учитывать сложные взаимосвязи между признаками. В научной литературе подтверждено, что случайный лес показывает высокую эффективность в задачах аудиоанализа [4].
Применение низкочастотного фильтра и нормализации громкости. Перед извлечением признаков из аудиофайла необходимо применить низкочастотный фильтр и провести нормализацию громкости. Это делается для улучшения качества данных и уменьшения влияния шума и вариаций громкости. Низкочастотный фильтр: Применение низкочастотного фильтра позволяет удалить высокочастотные компоненты сигнала, которые могут быть вызваны шумом или другими помехами. Это улучшает качество сигнала и делает его более подходящим для анализа. В научной литературе подтверждено, что использование низкочастотного фильтра улучшает точность распознавания звуковых событий [5]. Нормализация громкости: Нормализация громкости позволяет привести все аудиосигналы к одному уровню громкости, что уменьшает влияние вариаций громкости на результаты анализа. Это особенно важно для задач, где громкость сигнала может значительно варьироваться. В работе [6] показано, что нормализация громкости улучшает точность классификации звуковых событий.
Принятые допущения. В ходе разработки нами были приняты следующие допущения:
Качество данных: предполагается, что аудиоданные имеют достаточное качество и не содержат значительных искажений или шумов, которые не могут быть устранены с помощью низкочастотного фильтра.
Разнообразие данных: предполагается, что обучающая выборка включает достаточное количество примеров различных звуковых событий, включая звуки выстрелов, для обеспечения надежной тренировки модели.
Стабильность алгоритма: предполагается, что алгоритм случайного леса будет стабильно работать на новых данных, не входивших в обучающую выборку.
Результаты и эксперименты.
Формирование датасета. Формирование датасета разделено на несколько основных этапов: загрузка аудиофайла, его обработка, извлечения признаков, используемых для обучения модели, разметка и сохранение в структуру данных. Описание работы алгоритма представлено на блоксхеме (Рисунок 1).
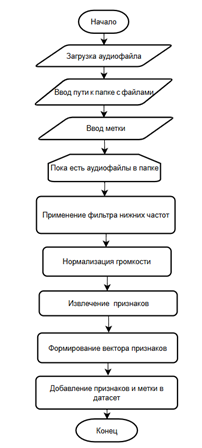
Рисунок 1. Алгоритм формирования датасета
Обучение модели. Модель была обучена с помощью встроенной функции fitcensemble. Fitcensemble принимает на вход вектор тренировочных признаков и вектор тренировочных меток. Полный код в среде MATLAB выглядит следующим образом:
load('audio_data.mat');
train_features = audio_data.train_features;
train_labels = audio_data.train_labels;
forest = fitcensemble(train_features, train_labels);
Проверка точности модели. Проверка была осуществлена на тестовом датасете, путём сравнения предсказанных меток с фактическими. Визуализация результатов осуществлена с помощью встроенных инструментов для построения графиков в MATLAB. Алгоритм Проверки точности модели и визуализация результатов: имеет следующий вид:
1) Загрузка данных:
- Загрузить файл audio_data.mat.
2) Извлечение тестовых признаков и меток:
- Извлечь тестовые признаки и метки из загруженного файла.
3) Оценка точности модели:
- Сравнить предсказанные метки с фактическими метками.
- Подсчитать количество правильных предсказаний.
- Вычислить точность модели как отношение количества правильных предсказаний к общему количеству меток.
- Вывести точность модели на экран.
4) Визуализация результатов:
- Создать график для сравнения фактических и предсказанных меток.
- Нарисовать фактические метки красными звездочками.
- Нарисовать предсказанные метки синими точками.
Результатом выполнения алгоритма будет являться график, изображённый на рисунке 2.
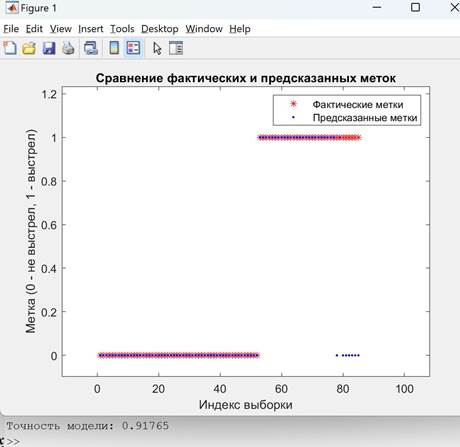
Рисунок 2. Точность модели при отсутствии зашумления
Для оценки точности модели при зашумлении входных данных при формировании тестового датасета были добавлены следующие строки:
noise = randn(size(audio));
snr = 20; % Отношение сигнал/шум в децибелах
noise = noise * std(audio) / (10^(snr/10));
audio = audio + noise;
Путём варьирования переменной snr были получены значения точности модели при различном отношении входного сигнала и шума (табл. 1).
Таблица.
Точность модели при различном уровне шума
|
Уровень шума |
Точность |
|
0 |
92 |
|
0,05 |
82 |
|
0,0556 |
72 |
|
0,0625 |
48 |
|
0,0714 |
20 |
|
0,0833 |
16 |
|
0,1 |
4 |
|
0,125 |
8 |
|
0,1667 |
8 |
|
0,25 |
4 |
|
0,5 |
0 |
|
1 |
0 |
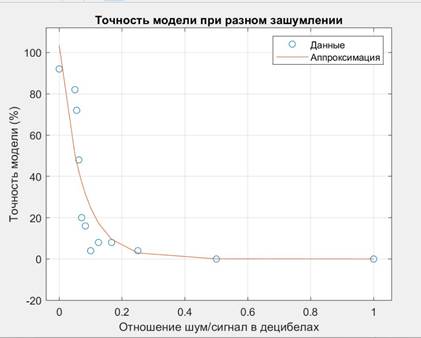
Рисунок 3. График точности модели при различном зашумлении
Заключение.
В ходе проведенного исследования была разработана и оценена система распознавания звука выстрела с использованием алгоритмов машинного обучения, в частности, алгоритма случайного леса. Для тренировки модели были выбраны различные признаки аудиоданных, включая среднее значение, стандартное отклонение, дисперсию, среднее значение абсолютных разностей между соседними отсчетами, сумму квадратов аудиоданных, эксцесс, асимметрия и мел-частотные кепстральные коэффициенты (MFCC). Эти признаки были выбраны на основе их способности эффективно представлять частотные и временные характеристики звукового сигнала.
Применение низкочастотного фильтра и нормализации громкости перед извлечением признаков позволило улучшить качество данных и уменьшить влияние шума и вариаций громкости. Это, в свою очередь, способствовало повышению точности модели.
Результаты экспериментов показали, что точность модели существенно зависит от уровня шума в входном сигнале. При низких уровнях шума (от 0 до 0.05) точность модели была высокой, достигая 92% и 82% соответственно. Однако с увеличением уровня шума точность модели значительно снижалась. При уровне шума 0.1 и выше точность модели падала до 4% и ниже, что свидетельствует о высокой чувствительности модели к шуму.
Таким образом, можно сделать вывод, что разработанная система распознавания звука выстрела на основе алгоритма случайного леса показывает высокую точность при низких уровнях шума. Однако для реальных условий эксплуатации, где уровень шума может быть значительным, необходимо разработать дополнительные методы обработки сигнала и улучшения устойчивости модели к шуму.
В будущем исследовании рекомендуется рассмотреть возможность использования более сложных алгоритмов машинного обучения, таких как глубокие нейронные сети, а также методы улучшения качества данных, такие как адаптивные фильтры и техники подавления шума. Это может позволить повысить точность модели при высоких уровнях шума и сделать систему более надежной в реальных условиях эксплуатации.
