Многоагентный искусственный интеллект в стратегиях
Журнал: Научный журнал «Студенческий форум» выпуск №39(90)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №39(90)
Многоагентный искусственный интеллект в стратегиях
Аннотация. В работе будет показано, что скоординированный искусственный интеллект с несколькими агентами оказывает значительное влияние на продолжительность игры даже в упрощенных играх. Несмотря на то, что существует достаточно методов для искусственного интеллекта с несколькими агентами, мы представляем новый подход, который делится информацией от каждого отдельного агента ии с другими агентами в их команде.
Ключевые слова: агентно-ориентированное моделирование, автономные агенты, многоагентные системы.
Введение. Для начала нам нужно понять, что такое агент. Агент – вычислительная система, помещенная во внешнюю среду, способная взаимодействовать с ней, совершая автономные рациональные действия для достижения целей. Под автономностью обычно понимают отсутствие прямого вмешательства человека или другой управляющей сущности. Также необходимо отметить, что внешняя среда не контролируется агентом, т.е. он способен лишь оказывать на нее влияние. Таким образом, многоагентная система – это направление искусственного интеллекта, которое для решения сложной задачи использует системы, состоящие из множества взаимодействующих агентов. Классический искусственный интеллект добавляет глубину игровому процессу, который имитирует игру против другого человека. Хотя конечный ИИ пытается быть совершенно аналогичен человеческому оппоненту, в реальности он часто терпит неудачу. Необходимо достичь тонкий баланс между неуязвимым всезнающим умным агентом и просто ходячей целью. Этот баланс сложно создать и еще сложнее поддерживать. Перед создателями игр стоит задача использовать состояние мира как его понимает игра, чтобы создать персонажа, имитирующего поведение человека. В результате ИИ часто настолько упрощается, что становится не более чем ходячим фоном в попытке сохранить его уязвимым. Предполагается, что команда врагов будет работать как единое целое и будет использовать численное преимущество, что они будут рассуждать и действовать стратегически. Но в реальности все по другому. В большинстве случаев команда ИИ персонажей - это всего лишь несколько экземпляров ИИ одного и того же персонажа.
Методология. Наша цель состоит в том, чтобы показать, что агенты работающие в команде (т. е. обмен информацией и целями ИИ), превзойдут агентов, реализующих одноагентный искусственный интеллект. Для этого мы придумали простую игру, в которой один игрок противостоит трем агентам противника. Программа была написана на C# для эмулятора PS Vita.Это игра в догонялки без препятствий. Игрок размещен в левой части экрана посередине, а три противника равномерно расположены в правой части (рис. 1).
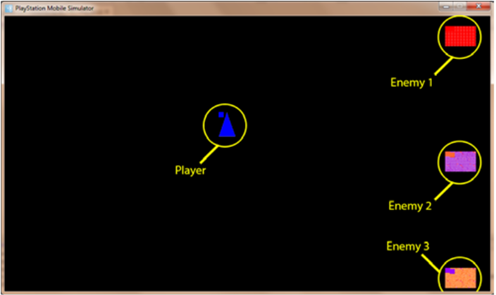
Рисунок 1. Начальные установки
Как только игра начинается, противники преследуют игрока, пока его не поймают. Как только игра начинается, противники преследуют игрока, пока его не поймают. Игра настроена на изменение скорости как игрока, так и противников и на изменение типа ИИ, который используют противники. Для этого исследования мы использовали два различных метода ИИ. Первым методом было прямое преследование. В этом методе противник непосредственно преследует игрока. Несмотря на то, что в игре несколько агентов, все они работают независимо от друг-друга. Второй используемый метод называется *прицелом и промахом*. Этот метод направлен на построение прямой линии к игроку, а затем координировать эту информацию с той же информацией от других противников. Этот угол преследования прямой линии регулируется на основе текущего формирования. Формирование — это расположение противоположных агентов по отношению к игроку.
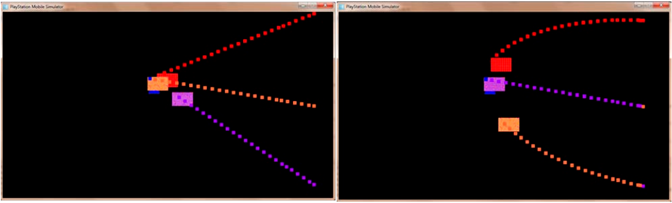
Рисунок 2. Примеры методов
По мере того как противники преследуют игрока, верхние и нижние противники обмениваются информацией о прицеливании. Это заставляет каждого целиться выше и ниже игрока, соответственно. Прицеливаясь выше и ниже, они удерживают игрока зажатым, когда они приближаются. Команда противников таким образом демонстрирует примитивную стратегию, окружая игрока и блокируя углы побега. Чтобы рассчитать правильные линии преследования для агентов, сначала были рассчитаны углы прямого преследования. Этот расчет был сделан с использованием евклидова расстояния, рассчитанного с помощью векторной записи. Результирующий вектор — это угол прямого преследования. Этот вектор затем взвешивается против вектора своего противоположного противника, чтобы получить вектор преследования противника выше или ниже игрока. Чтобы быть точным, предположим, что верхний противник в C-формировании вычисляет угол прямого преследования, равный -30° относительно игрока. Затем нижний оппонентрассчитывает угол прямого преследования, который будет равен + 40° относительно игрока. Если бы противники обратились к этим заголовкам, они бы реализовали алгоритм *прямого преследования*. В алгоритме «прицел и промах» каждый противник регулирует свой угол преследования, исследуя сначала свою позицию в строю, затем свой угол преследования и наконец скорректированный угол направления. В приведенном выше примере верхний противник корректирует свой курс, рассматривая равновесную формулировку своего собственного угла прямого преследования с углом прямого преследования для нижнего противника. В этом примере верхний противник берет свой собственный курс -30° и добавляет курс нижнего противника (40°), чтобы достичь курса 10°. Этот новый угол курса гарантирует, что верхний противник будет стремиться выше игрока и не даст ему столкнуться с игроком (и, таким образом, его легко избежать). Нижний противник также настраивает свой курс на -10°, чтобы прицелиться ниже игрока. Эти два создадут эффект пинцета, чтобы зажать игрока между двумя внешними противниками. Когда верхний и нижний противники приближаются с краев, они остаются за пределами непосредственно приближающегося центрального противника, чтобы окружить и захватить игрока (Рис.3).

Рисунок 3. Метод прицела и промаха
Полученные результаты. Исследование показало, что две стратегии работали совершенно по-разному. Стратегия прямого преследования ловила игрока в среднем за 21 секунду на испытание, (при стандартном отклонении 9,52с), при этом некоторые игры заканчивались только после того, как игрок уставал бегать по экрану. В этих последних случаях было ясно, что он мог убегать от противников так долго, как он хотел. Стратегия прицела и промаха показала явное преимущество, игры заканчивались в среднем за 5,63 секунды на испытание (при стандартном отклонении 1,68с). Стратегия прямого преследования движется прямо к игроку, и три противника объединяются. Поскольку их ИИ одинаков, они выступают как один противник, отказываясь от своего численного преимущества. Это быстро выравнивает шансы для игрока, поскольку легче избежать одного противника, чем избежать трех.
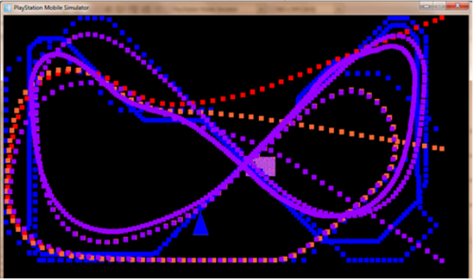
Рисунок 4. Пути метода прямого преследования
На 4 рисунке показаны пути преследования после долгой игры с более простым ИИ. Углы начального преследования ИИ с прицелом и промахом показывают, что верхний и нижний противники приближаются к игроку со своих соответствующих сторон и изгибаются только когда они приближаются к игроку. Это достаточно ясно показывает формирование выступа и иллюстрирует, почему этот более стратегический многоагентный подход работает лучше.
Заключение. Было показано, что искусственный интеллект с одним агентом, даже если он работает на нескольких агентах одновременно, не может превзойти ИИ с несколькими агентами, который координирует его поведение. Испытания ясно показали, что та же самая простая игра была значительно сложнее для участников, когда ИИ работал вместе, чтобы поймать их в ловушку.
