Статья:




РАЗРАБОТКА МАТЕМАТИЧЕСКОГО ОБЕСПЕЧЕНИЯ ИНФОРМАЦИОННОЙ СИСТЕМЫ ЧИТАТЕЛЬСКОГО ДНЕВНИКА С СИСТЕМОЙ ПЕРСОНАЛЬНЫХ РЕКОМЕНДАЦИЙ
Конференция: CCCVIII Студенческая международная научно-практическая конференция «Молодежный научный форум»
Секция: Технические науки
Выходные данные
Кравцова А.А., Леньшина Д.С. РАЗРАБОТКА МАТЕМАТИЧЕСКОГО ОБЕСПЕЧЕНИЯ ИНФОРМАЦИОННОЙ СИСТЕМЫ ЧИТАТЕЛЬСКОГО ДНЕВНИКА С СИСТЕМОЙ ПЕРСОНАЛЬНЫХ РЕКОМЕНДАЦИЙ // Молодежный научный форум: электр. сб. ст. по мат. CCCVIII междунар. студ. науч.-практ. конф. № 29(308). URL: https://nauchforum.ru/archive/MNF_interdisciplinarity/29(308).pdf (дата обращения: 29.07.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 0 голосов
Мне нравится0
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

CCCVIII Студенческая международная научно-практическая конференция «Молодежный научный форум»
РАЗРАБОТКА МАТЕМАТИЧЕСКОГО ОБЕСПЕЧЕНИЯ ИНФОРМАЦИОННОЙ СИСТЕМЫ ЧИТАТЕЛЬСКОГО ДНЕВНИКА С СИСТЕМОЙ ПЕРСОНАЛЬНЫХ РЕКОМЕНДАЦИЙ
Кравцова Анна Александровна
студент, Сибирский государственный университет телекоммуникаций и информатики, РФ, г. Новосибирск
Леньшина Дарья Сергеевна
студент, Сибирский государственный университет телекоммуникаций и информатики, РФ, г. Новосибирск
В эпоху цифровизации книжный рынок переживает глобальные изменения: рост популярности электронных книг и стриминговых сервисов. Издательствам необходимо внедрять цифровые технологии для усиления конкурентных позиций на рынке и, соответственно, повышения продаж. Таким образом, актуальность темы данной статьи обусловлена ростом конкуренции на книжном рынке и необходимостью персонализации взаимодействия с читателями.
Системы рекомендаций позволяют пользователю выбрать среди всех доступных объектов именно те, которые будут ему интересны. Эти системы обрабатывают информацию о различных объектах, а также о том, какие объекты пользователи купили, посмотрели, послушали и т.д. Имея эти данные, можно быстро и качественно отфильтровать наиболее подходящие конкретному пользователю объекты.
Назначение читательского дневника с системой персональных рекомендаций – предоставлять пользователям персонализированные рекомендации книг на основе релевантной информации.
Ограничения:
- Алгоритм ограничен данными, доступными о пользователе (история чтения, предпочтения и т. д.).
- Эффективность алгоритма зависит от качества и количества данных, доступных о пользователе.
- Алгоритм может не учитывать определенные нюансы и предпочтения пользователя, не отраженные в данных.
Характеристики качества решения:
- Рекомендации должны быть релевантными для интересов пользователя.
- Алгоритм должен генерировать рекомендации в разумное время, обеспечивая удобство использования для пользователя.
Метод фильтрации на основе контента (content-based filtering) для персональных книжных рекомендаций основывается на анализе характеристик книг и предпочтений пользователей [1].
Каждая книга описана набором характеристик. Эти характеристики могут быть представлены в виде вектора V:
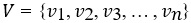
Где vi — это значение i-й характеристики.
Профиль пользователя можно описать как вектор предпочтений, основанный на его истории чтения и оценках книг:
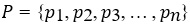
Где pi — это значение i-й характеристики, отражающий интерес пользователя к данной характеристике.
Для того чтобы рекомендовать книги пользователю, необходимо вычислить сходство между профилем пользователя и характеристиками книг. Это можно сделать с помощью косинусного сходства. Косинусное сходство между вектором пользователя и вектором книги можно вычислить по формуле 3.1
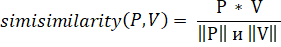
Где P * V — скалярное произведение векторов, а 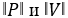 — нормы векторов.
— нормы векторов.
На основе вычисленного сходства можно сформировать список рекомендованных книг. Например, можно выбрать k книг с наибольшим значением сходства:
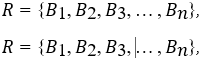
Где R — это набор рекомендованных книг, а Bi — это книги с наибольшими значениями сходства.
Алгоритм решения:
- Сбор данных о прочитанных книгах и выставленных оценках.
- Обработка данных.
- Произведение расчётов сходства.
- Формирование рекомендаций.
- Вывод рекомендаций пользователю.
На рисунке 1 представлена диаграмма состояний функции «Предоставление персональных рекомендаций».
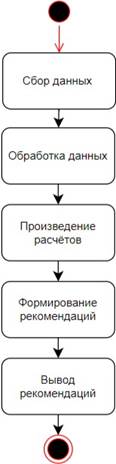
Рисунок 1. Диаграмма состояния функции «Предоставление персональных рекомендаций»
Список литературы:
1. Рытиков А. В. Описание работы рекомендательных систем на основе совместной фильтрации и контент ориентированных методах // Экономика и социум. 2022. №12-1 (103). URL: https://cyberleninka.ru/article/n/opisanie-raboty-rekomendatelnyh-sistem-na-osnove-sovmestnoy-filtratsii-i-kontent-orientirovannyh-metodah (дата обращения: 23.04.2025).
