Система обнаружения объектов в реальном времени с использованием глубокого обучения слепых людей
Конференция: XLII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»
Секция: Информатика, вычислительная техника и управление

XLII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»
Система обнаружения объектов в реальном времени с использованием глубокого обучения слепых людей
Аннотация. Во всем мире около 39 миллионов слепых и около 246 миллионов человек со слабым зрением. Без видения довольно сложно выполнять повседневную работу, из-за которой человек всегда от кого-то зависит. Наш проект помогает этим людям с нарушениями зрения. В этой статье рассказывается о системе помощи слепым. Мы создали беспроводную систему, которая состоит из ноутбука в качестве сервера и мобильного телефона Android в качестве клиента. Мы создали приложение, которое соединит ноутбук и мобильный телефон и имеет очень удобный интерфейс.
Ключевые слова: слепые люди; система обнаружения; обучение.
В этом прекрасном мире, где большинство из нас наделено хорошим зрением, есть много людей с нарушениями зрения. Эти люди всегда зависят от других людей, которые помогают им во всем. Следовательно, чтобы преодолеть эту проблему, мы создали эту систему.
Наша система называется «Система помощи слепым». Обзор нашей системы таков: есть ноутбук, который выполняет роль сервера и обрабатывающей машины, и мобильный телефон, который снимает изображения. Мобильный телефон фиксирует изображения в реальном времени через свою камеру и отправляет эти изображения на ноутбук. Ноутбук анализирует эти изображения и отправляет человеку голосовое сообщение [1]. Он также сообщает расстояние, на котором находится объект. Чтобы использовать это эффективно, мы создали приложение, которое соединяет ноутбук и мобильный телефон. Сквозь это одно приложение фиксирует изображения в реальном времени. В нашем проекте можно идентифицировать как предметы, так и человека перед ними.
В нашем проекте используется алгоритм обнаружения одиночного выстрела для нахождения нескольких объектов. В нашем проекте у нас есть всего 90 классов объектов, которые обучаются и затем конвертируются в API. Используя этот алгоритм SSD, мы получаем точность 98 % при тестировании этих моделей.
ResNet, что означает остаточная сеть, в основном представляет собой сверточную нейронную сеть, которая предназначена для сотен или тысяч сверточных слоев. В ней хранятся сопоставления удостоверений. Она пропускает слои, которые изначально ничего не делают. Она повторно использует активации из предыдущих слоев. Из-за пропуска слоев она сжимает сеть, что позволяет быстро обучаться [4].
Методология/экспериментальная часть
Используемые библиотеки.
1. OpenCV – библиотека компьютерного зрения с открытым исходным кодом). Как следует из названия, это библиотека машинного обучения и компьютерного зрения. В основном используется для обнаружения людей, лиц, объектов. Ее также можно использовать для отслеживания или обнаружения движущихся объектов, она также классифицирует человеческие действия в видео. Мы использовали это для обнаружения объектов и человека через камеру.
2. Matplotlib – это библиотека, которая производит графическое представление результатов. Она работает аналогично Matlab. Эта библиотека позволяет вносить изменения в рисунок, вычерчивая линии, декорируя график метками.
3. Tensorflow. TensorFlow в основном используется для построения моделей глубокого обучения. Это библиотека, которая предоставляет набор рабочих процессов для разработки и обучения моделей глубокого обучения.
4. Numpy – это библиотека, которая поддерживает большое количество матриц. Она используется в программировании на Python. Она также поддерживает многомерные арри, а также многие высокоуровневые функции. Основу стека машинного обучения составляет эта библиотека.
5. Pyttsx3 – это библиотека, которая используется в Python для преобразования текста в речь. Эта библиотека совместима с Python 2 и 3, а также работает в автономном режиме.
Мы использовали эту библиотеку для преобразования текста предсказанного изображения в речь. Общий поток нашего проекта таков: сначала реальные изображения захватываются через мобильный телефон, они отправляются в систему, затем выполняются обработка и тестирование, и, наконец, результат обнаруженного объекта передается в виде звука. Он также показывает расстояние, на котором находится объект. Ниже приведены схемы и обзор нашего проекта [3].
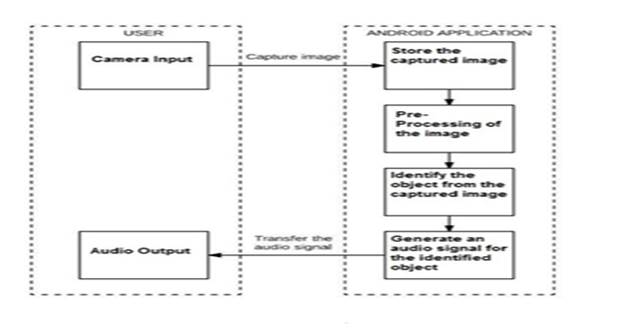
Рисунок. API-интерфейсы TENSORFLOW
Интерфейс прикладного программирования – это полная форма API. Преимущество, которое дает использование API, заключается в том, что он предоставляет нам набор общих операций, из-за чего нам не нужно писать код для программы с нуля. Мы можем сказать, что они весьма полезны, а также эффективны. API-интерфейсы обеспечивают нам удобство, и, следовательно, они экономят время. API обнаружения объектов TensorFlow – это в основном структура для создания сети глубокого обучения, которая решает проблемы обнаружения объектов. В их структуре есть обученные модели, которые они называют Model Zoo. Это включает в себя набор данных COCO, набор данных KITTI и набор данных Open Images. Эти модели можно использовать, если мы хотим ограничить нашу модель категориями в этом наборе данных.
Наборы данных
Наборы данных, которые мы здесь использовали, называются наборами данных COCO. COCO означает общие объекты в контексте. Слово контекст говорит о том, что изображения в наборе данных COCO относятся только к повседневной жизни. COCO была инициативой по сбору изображений, которые отражают повседневную жизнь в коротких повседневных сценах и предоставляют контекстную информацию. В повседневной жизни мы сталкиваемся с множеством объектов их различных типов, объект может иметь несколько видов, и можно найти несколько объектов, и каждый должен быть помечен как отдельный объект, чтобы правильно различать и сегментировать. Надлежащая маркировка и сегментация объектов на изображениях обеспечивается поставщиками наборов данных COCO. Мы воспользовались преимуществами помеченных, а также сегментированных изображений, чтобы создать лучшую и надежную модель обнаружения объектов. COCO – это крупномасштабное обнаружение объектов, сегментация и набор данных с субтитрами. Версия COCO 2017 содержит изображения, ограничивающие рамки и метки для версии 2017. Некоторые изображения из наборов поездов и проверок не имеют аннотаций. Есть разница в разделении поездов / валидаций / тестов, иначе COCO 2014 и 2017 использует те же изображения. Нет никаких обозначений для тестирования разделения (только изображения). Только 80 классов используются данными, хотя COCO определяет 91 класс. Панотптические аннотации определяют 200 классов, но используют только 133. Значения Test/train и validation составляют 40 670; 118 287 и 5000 соответственно.
Алгоритм обнаружения объектов
Архитектура SSD
SSD состоит из двух компонентов: SSD-головки и магистральной модели. Базовая модель в основном представляет собой обученную сеть классификации изображений в качестве экстрактора признаков. Как и ResNet, это обычно сеть, обученная на ImageNet, из которой был удален последний полностью связанный слой классификации. Головка SSD – это всего лишь один или несколько сверточных слоев, добавленных к этой магистрали, а выходы интерпретируются как ограничивающие прямоугольники и классы объектов в пространственном расположении активаций последних слоев [5]. Таким образом, мы остаемся с глубокой нейронной сетью, которая способна извлекать семантическое значение из входного изображения с сохранением пространственной структуры изображения, хотя и с более низким разрешением. Для входного изображения магистраль дает 256 карт функций 7×7 в ResNet34. Ячейка сетки вместо использования скользящего окна SSD разделяет изображение с помощью сетки, и каждая ячейка сетки отвечает за обнаружение объектов в этой области изображения. Обнаружение объектов в основном означает предсказание класса и местоположения объекта в этой области. Фоновый класс рассматривается, если объект отсутствует и местоположение игнорируется. Например, мы могли бы использовать сетку 4×4 в приведенном ниже примере.
Каждая ячейка сетки может выводить форму объекта и его положение. Якорь и принимающее поле вступают в игру, когда в одной ячейке сетки есть несколько объектов или нам нужно обнаружить несколько объектов разной формы. Якорь: несколько якорей / предыдущих ячеек можно назначить каждой ячейке сетки в SSD. Эти назначенные якорные блоки предварительно определены, и каждый из них отвечает за размер и форму в ячейке сетки. SSD использует фазу согласования во время обучения, так что есть соответствующее совпадение якорного ящика с ограничивающими прямоугольниками каждого наземного объекта истинности внутри изображения [2]. За прогнозирование класса этого объекта и его местоположения отвечает блок привязки с наивысшей степенью перекрытия с объектом. После обучения сети это свойство используется для обучения сети и для прогнозирования обнаруженных объектов и их местоположения. Практически каждый блок привязки задается с соотношением сторон и уровнем масштабирования. Что ж, мы знаем, что не все предметы имеют квадратную форму. Некоторые короче, некоторые длиннее, а некоторые в разной степени шире. Архитектура SSD позволяет учитывать это заранее заданным соотношением сторон якорей. Различные соотношения сторон могут быть указаны с помощью параметра ratios якорных ячеек, связанных с каждой ячейкой сетки на каждом уровне масштабирования / масштабирования.
Результат
Предлагаемая система успешно обнаруживает 90 объектов, маркирует их, а также показывает свою точность. Модель также рассчитывает расстояние от объекта до камеры и дает голосовую обратную связь, когда человек с камерой приближается к объекту. Набор данных был обучен на две разные модели – SSD Mobilenet V1 и SSD Inception V2, однако модель SSD Mobilenet V1 показала меньшую задержку и быстрее обнаруживала объекты.
Заключение
Предлагаемая система является инициативой для решения проблем слепых. Многие устройства, такие как ультразвуковые датчики, традиционная белая трость с датчиками, в настоящее время используются для помощи слепым. Предлагаемая система устраняет многие ограничения старых систем для слепых. Система получает изображение в реальном времени из мобильного приложения и отправляет его модели на ноутбуке, которая затем обнаруживает объект, вычисляет расстояние между человеком и объектом и дает звуковую обратную связь, когда человек приближается к объекту.
