MACHINE VISION-BASED TRAFFIC LIGHT RECOGNITION SYSTEM
Журнал: Научный журнал «Студенческий форум» выпуск №12(363)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №12(363)
MACHINE VISION-BASED TRAFFIC LIGHT RECOGNITION SYSTEM
Abstract. This project addresses the need for automatic detection and recognition of traffic lights in intelligent transportation and autonomous driving scenarios. Based on deep learning and computer vision, an efficient traffic light recognition system was developed. In this system, YOLO is trained to detect traffic lights and identify their states (red, green, and yellow). OpenCV is then used for image preprocessing, including denoising, edge detection, and color space conversion, to improve the robustness and accuracy of detection and to better integrate with the YOLO model. A BiFPN module is also introduced to fuse multi-scale features and further improve target detection performance. The system can recognize traffic lights, evaluate detection results, and save the output. Evaluation metrics such as accuracy, recall, and missed detection rate are used to assess system performance under different environments and weather conditions. The core of the system combines YOLO-based detection, BiFPN-based multi-scale feature fusion, and OpenCV image processing. This system can provide technical support for traffic safety applications and has practical potential in intelligent transportation systems and autonomous driving.
Keywords: deep learning; computer vision; opencv; yolo; intelligent transportation systems; autonomous driving.
1. Introduction With the rapid economic and social development of China, vehicle ownership has increased sharply, and urban road traffic has grown accordingly[1]. Traditional traffic management methods have become increasingly difficult to apply in complex traffic environments, and problems such as congestion and frequent traffic accidents have become important constraints on urban development. At the same time, autonomous driving and intelligent transportation systems (ITS) are moving from research to practical application[2]. As the main traffic control signal on the road, traffic lights must be recognized accurately and in real time to support autonomous driving and intelligent traffic management. Traditional traffic light recognition methods often rely on fixed sensors or simple image processing techniques, which usually suffer from low accuracy, weak environmental adaptability, and limited real-time performance. These methods struggle in complex scenarios such as cloudy weather, rain, strong light, long distances, and target occlusion. In recent years, however, rapid progress in machine vision and deep learning has provided a new solution for intelligent traffic light recognition[3]. By building deep neural network models, visual features of traffic lights can be extracted automatically, making accurate detection and state recognition possible across multiple scenarios. This has become an active research topic in intelligent transportation and offers technical support for practical traffic problems[4]. In response to current needs in intelligent transportation, this study develops a machine vision-based traffic light recognition system aimed at building a low-cost, robust solution through algorithm optimization and system integration, thereby addressing the limits of traditional methods and providing a practical option for grassroots traffic applications.
2. Overall System Architecture Design
The traffic light recognition system developed in this project adopts an end-to-end architecture and consists of five core modules: data acquisition, image preprocessing, traffic light detection, state classification, and result output and storage[5]. These modules work together to complete the traffic light recognition task. The overall process is as follows: the data acquisition module collects traffic light images or videos and sends them to the image preprocessing module for denoising, color space conversion, and other operations; the preprocessed images are then passed to the traffic light detection module, where the YOLOv5+BiFPN model is used to accurately localize traffic lights; the localized traffic light regions are then sent to the state classification module to classify color states (red, green, and yellow) and arrow directions (straight, left, and right); finally, the result output and storage module displays the recognition results as text in the visual interface and saves the detection results and image data locally. This architecture adopts a modular design, allowing each module to be developed independently and integrated flexibly. It also supports later function expansion and algorithm optimization while reducing maintenance costs.
3. YOLOv5-Based Target Detection and State Classification Algorithm
The core algorithms of this system consist of three parts: an image preprocessing algorithm, a BiFPN-based multi-scale feature fusion algorithm, and a YOLOv5-based target detection and state classification algorithm[6]. These components work together to achieve efficient traffic light detection and accurate recognition.
YOLOv5 is a lightweight single-stage object detection algorithm with fast detection speed, high accuracy, and easy deployment[7]. For this reason, it is selected as the core detection algorithm of this system and is further optimized for the task. At the dataset level, Mosaic data augmentation is used to generate new training samples by randomly combining four images, which improves dataset diversity. Adaptive anchor calculation and adaptive image scaling are also used so that the model can better match the characteristics of the traffic light dataset. For target detection, the input image is divided into multiple grid cells, and each cell predicts a fixed number of bounding boxes. Non-maximum suppression (NMS) is then used to retain the bounding boxes with the highest confidence and complete accurate traffic light localization. For state classification, features are extracted from the localized traffic light regions, and the lights are divided into eight categories according to color and shape, so that color states and directional arrow instructions can be identified accurately, with the classification results and confidence scores output at the same time. At the loss-function level, GIoU Loss is used to measure the difference between predicted boxes and ground-truth boxes more accurately and further improve localization performance. The YOLOv5 workflow is shown below:
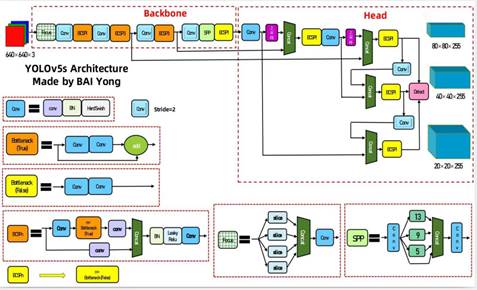
Figure 3.1 YOLOv5 Algorithm Flowchart
4. System Development and Functional Implementation
4.1 Visual Interface Design
Based on Python 3.8 and PyQt5, the system provides a visual user interface running on Windows 11. The interface follows a simple and user-friendly design and is mainly divided into three areas. The main image display area is used to show imported traffic light images and detection results, giving real-time feedback on traffic light positions and states. The file path display area clearly shows the path of the currently imported image, allowing users to confirm the detection target. The function button area contains three main buttons—“Select Object,” “Start Detection,” and “Exit System”—which allow quick image import, detection start, and system exit. The core functions of the system include image/video import, model loading, real-time detection, and result saving.
4.2 Implementation of Core System Functions
The system provides a complete traffic light recognition workflow, with four main modules: image/video import, model loading, real-time detection, and result saving. These modules work together to ensure the practicality and completeness of the system. The system supports single-image and batch-image import, as well as common video formats such as JPG, PNG, and MP4, which makes it suitable for different scenarios. It can quickly load the optimal YOLOv5+BiFPN weight file (best.pt) and also supports model replacement and updating for later algorithm improvement. Imported images and videos can be processed in real time, and the system quickly outputs information such as traffic light position, category, and confidence score. At the same time, the detection results, including categories, confidence scores, and evaluation indicators, as well as annotated image data, can be saved locally for later export, review, and data analysis.
5. Experimental Validation and Result Analysis
5.1 Comparison of Simulation Experiment Data
The traffic light recognition system designed in this study uses YOLOv5 as the core detection framework and is implemented on the Windows platform. A convenient visual interface is built with PyQt5, enabling a complete visual workflow from image acquisition and file input to algorithm detection and result output. In this study, the traffic light display states are divided into eight categories: red left-turn arrow (rl), green left-turn arrow (gl), red straight arrow (ru), green straight arrow (gu), red circular light (r), green circular light (g), red right-turn arrow (rr), and green right-turn arrow (gr).

Figure 5.1 Training Recognition Results
Two important weight files are stored in the weights folder: best.pt and last.pt. The file best.pt represents the best-performing weights obtained during training, while last.pt stores the weights from the final training epoch.
Table 5.1
Confusion Matrix
|
Predicted /Actual |
Positive |
Negative |
|
Positive |
True Positive (TP) |
False Positive (FP) |
|
Negative |
False Negative (FN) |
True Negative (TN) |
After the model is trained using these weight files, a confusion matrix can be generated to evaluate model performance, as shown in Figure 5.2. Each row in the matrix represents the true class of the data, while each column represents the class predicted by the model. TP (true positive) means that a positive sample is correctly predicted as positive. FN (false negative) means that a positive sample is incorrectly predicted as negative. FP (false positive) means that a negative sample is incorrectly predicted as positive. TN (true negative) means that a negative sample is correctly predicted as negative.
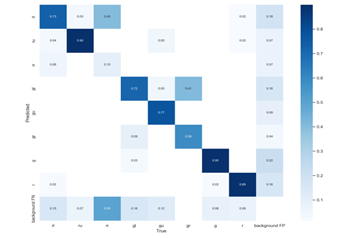
Figure 5.2 Confusion Matrix
The F1 score is a measure of classification performance ranging from 0 to 1. A higher value indicates better and more stable performance. The F1 score balances precision and recall and helps evaluate the overall ability of the classifier to identify positive samples while avoiding misclassification. Figure 5.3 shows the relationship between the F1 score and the confidence threshold.
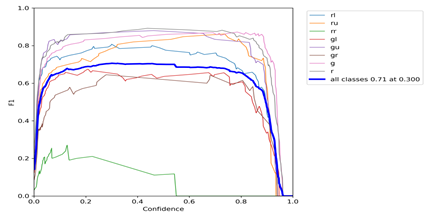
Figure 5.3 F1 Curve
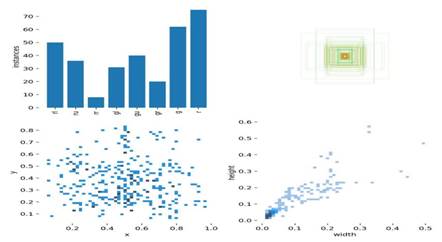
Figure 5.4 Training Statistics
As shown in Figure 5.4, the first panel presents the number of red and green left-turn arrows, right-turn arrows, and red and green circular traffic lights in the training set. The second panel shows the size and number of bounding boxes. The third panel presents the positions of target center points, and the last panel shows the height-to-width ratio of the targets. Together, these charts provide an overview of the dataset, target size, location, and shape.
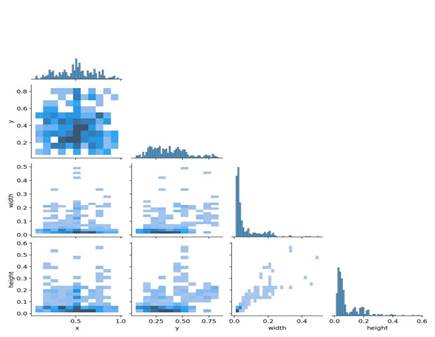
Figure 5.5 Color Matrix
Figure 5.5 shows the relationships among the horizontal and vertical coordinates of the center points and the height and width of the bounding boxes, indicating where useful information can be extracted from the images. The figure shows that the center points of the detected targets are mostly concentrated in the central area of the image, and that the height and width of most extracted boxes do not exceed one tenth of the image size.
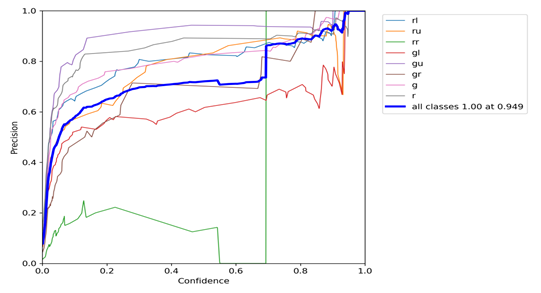
Figure 5.6 Precision for a Single Class
Figure 5.6 shows the relationship between precision for a single class and the confidence threshold. When the model assigns a probability higher than a given threshold to a certain class, the prediction is regarded as belonging to that class. Increasing the confidence threshold can improve detection precision, but it may also cause some real samples to be ignored because their predicted probabilities are slightly lower.
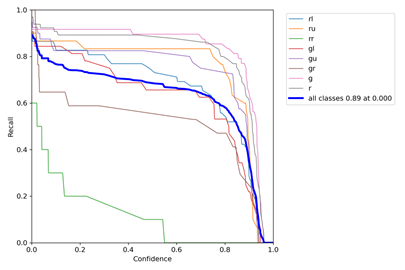
Figure 5.7 Recall for a Single Class
Figure 5.7 shows the curve between confidence threshold and recall. When the confidence threshold is lower, the class coverage is more complete. In this case, missed detections are less likely, but false detections are more likely to occur.
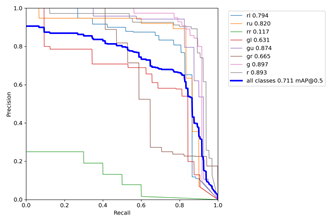
Figure 5.8 Relationship Between Precision and Recall
The PR curve in Figure 5.8 shows the relationship between precision and recall, and mAP is the metric used to evaluate this relationship. Ideally, the curve should be close to (1,1), and mAP should be close to 1, which indicates the best classification performance. As shown in the figure, the average recognition precision in this study is 71.1%. Here, box_loss represents the error between the predicted box and the ground-truth box; a smaller value indicates more accurate localization. obj_loss represents the confidence of the network in the presence of a target; a smaller value indicates better target detection. cls_loss measures classification correctness; a smaller value indicates better classification. mAP@0.5:0.95 (mAP@[0.5:0.95]) represents the average mAP over different IoU thresholds from 0.5 to 0.95 with a step size of 0.05 (0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, and 0.95), while mAP@0.5 represents the average mAP when the IoU threshold is greater than 0.5. The training loss values and evaluation metrics are shown in the figure below:
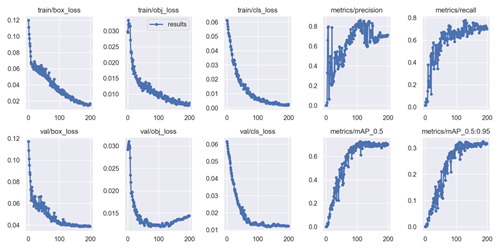
Figure 5.9. Training Loss and Evaluation Metrics
5.2 Discussion of Results
The traffic light recognition system designed in this study uses the YOLOv5 algorithm and is implemented on the Windows platform. A visual interface is built with PyQt5 to display the full process of image acquisition, input, detection, and output, making it straightforward to obtain traffic light information from road scenes.
By running the ui.py file, users can enter the system interface, select the image to be recognized, and start detection. The detection results are shown in the figures below. The output consists of two letters. The first letter represents the color, red (r) or green (g). If the traffic light is arrow-shaped, the second letter represents the direction: straight (u), left (l), or right (r). If the light is circular, only red (r) or green (g) is used, indicating whether straight movement is allowed on that road section. Recognition results for different types of traffic lights are shown in Figures 5.10 and 5.11.

Figure 5.10 Recognition Results for Standalone Traffic Lights
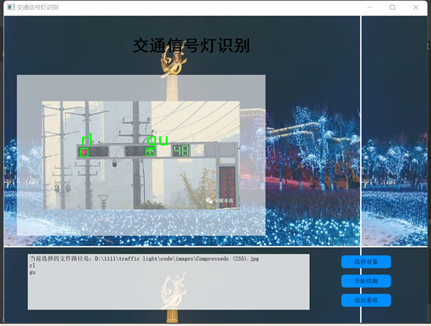
Figure 5.11 Recognition of Mast-Arm Traffic Lights

Figure 5.12 Detection Accuracy
The above experiments show that the traffic light recognition system developed in this study can accurately recognize both standalone traffic lights and mast-arm traffic lights, including whether vehicles are allowed to go straight, turn left, or turn right, and that its performance remains stable under different weather conditions. As shown in Figure 5.12, the detection accuracy of the system under different distances and weather conditions is between 0.8 and 0.9, which indicates that the system has good robustness and is suitable for traffic light detection in relatively complex road environments.
6. Conclusion and Future Work
This undergraduate innovation project carried out the full research and design process for a machine vision-based traffic light recognition system and ultimately produced a system that balances accuracy and practical use. The project built a multi-scenario traffic light dataset, combined and optimized YOLOv5 and BiFPN to improve small-target detection, and developed a visual interface based on OpenCV and PyQt5. Experimental results show an average recognition precision of 71.1% across multiple scenarios, a detection confidence range of 0.8–0.9, and good environmental adaptability and real-time performance. The project also helped the team develop practical and collaborative skills in related technologies. At the same time, the project revealed several limitations, including insufficient recognition accuracy in extreme scenarios and the need for better model lightweighting. Future work will focus on algorithm optimization, multimodal fusion, function expansion, and practical deployment in order to further improve system performance and promote real-world application.
