Архитектура высокопроизводительного сервиса для эффективной обработки больших объемов данных
Журнал: Научный журнал «Студенческий форум» выпуск №35(86)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №35(86)
Архитектура высокопроизводительного сервиса для эффективной обработки больших объемов данных
Аннотация. В данной статье рассмотрена актуальная задача по проектированию и разработке высокопроизводительного сервиса для эффективной обработки больших объемов данных, приведен анализ различных технологий для ее решения, среди которых выбраны наиболее эффективные. Приведены архитектура сервиса и пример системы для внедрения проекта.
Ключевые слова: высокопроизводительный сервис, ORM, база данных, .NET Core.
С каждым годом количество данных, размещаемых в сети Интернет, а также пересылаемых по сети, растет [1]. Все больше и больше людей становятся активными пользователями различных веб-сервисов и бизнес-приложений. В связи с этим все чаще упоминают так называемые высокопроизводительные или высоконагруженные сервисы. Это сервисы, которые характеризуются большим количеством одновременно подключенных пользователей, а также большим объемом обрабатываемых данных. Вследствие актуальности данных сервисов все более важной является прикладная задача по созданию высоконагруженных приложений. Данная задача включает в себя проектирование и разработку высокопроизводительного кроссплатформенного сервиса и специального хранилища для данных. Поскольку типы данных, обрабатываемые приложением, могут изменяться со временем, то преимуществом приложения является разработка такого хранилища, которое не строго привязано к определенному типу базы данных и предоставляет возможность поменять базу данных без больших временных и материальных затрат. Взаимодействие основных частей приложения происходит по принципу отправки сервисом команд создания, модификации и удаления определенных данных хранилищу.
- Анализ возможных решений задачи
Хранилище информации для данной задачи представляет собой базу данных. Для работы с базами данных одной из самых популярных и действенных моделей является объектно-реляционное отображение (англ. Object-Relational Mapping, ORM) [2]. Данная технология позволяет записывать в базу данных и получать из неё объекты, описанные в определенной программе, то есть является «прослойкой» между базой данных и кодом программы. Такая особенность позволяет оперировать элементами языка программирования (классами, объектами и т. д.) и дает возможность автоматического создания SQL-запросов. Кроме того, не нужно создавать новые SQL-запросы при переносе приложения на другую систему управления базами данных, поскольку за это отвечает низкоуровненый драйвер ORM [3]. Таким образом, использование технологии объектно-реляционного отображения является целесообразным при решении поставленной задачи по проектированию и разработке высокопроизводительного сервиса. Важным аспектом при подготовке к решению задачи является выбор языка программирования. Учитывая специфику данной задачи, необходимо выбрать такой язык программирования, который позволит обеспечить высокую производительность сервера. Язык C++ считается лидером по использованию для разработки высоконагруженных сервисов благодаря тому, что дает программистам гораздо больше «контроля» над кодом, к примеру, над управлением памятью. Это позволяет оптимизировать алгоритмы для достижения лучших показателей производительности. Однако при тщательном обзоре различных решений так и не было найдено ни одной кроссплатформенной библиотеки, поддерживающей технологию ORM и произвольные виды систем управления базами данных, а также написанной на языке программирования C++. Поэтому для решения поставленной задачи необходимо рассмотреть другие варианты, среди которых наиболее подходящими являются языки Java и С# (платформа .NET). ORM-решением для языка Java является технология Hibernate. Эта технология является мощной и имеет высокие показатели производительности [4]. Платформа .NET предлагает несколько технологий – NHibernate, Entity Framework, ADO.NET. Последняя из них является наиболее производительной, однако не поддерживает такого широкого функционала, как Entity Framework и NHibernate [5-7]. 23 сентября 2019 года компанией Microsoft была выпущена новая версия платформы .NET Core – 3.0 [8]. Среди нововведений можно выделить многочисленные оптимизации кода, в результате чего повысились показатели производительности всей платформы в целом, новый SQL-клиент, которого можно подключить с помощью Entity Framework и ADO.NET, а также новая версия технологии Entity Framework Core с поддержкой облачной службы базы данных Azure Cosmos DB. Данная служба была названа лидером в отчете The Forrester Wave: Big Data NoSQL за первый квартал 2019 года [9]. Соответственно, платформа .NET Core 3.0 может предоставить инструменты для эффективной работы с большими объемами данных, а также поддержку смены системы управления базы данных без особых затрат. Кроме того, .NET Core обладает свойством кроссплатформенности, в отличие от .NET Framework. Таким образом, исходя из анализа технологий, наиболее подходящей для решения поставленной задачи является платформа .NET Core 3.0.
- Архитектура сервиса
На рисунке 1 представлен пример системы для внедрения описанного сервиса, а также его структура.
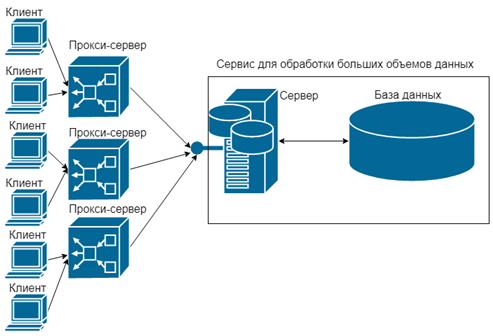
Рисунок. 1. Пример системы для внедрения сервиса
Сервис состоит из двух основных частей – высокопроизводительного сервера, позволяющего принимать информацию и обрабатывать ее определенным образом, а после этого сохранять ее, и хранилища, то есть базы данных. База данных может во временем изменяться, поэтому «общение» между сервером и хранилищем происходит при помощи технологии ORM путем запросов на получение, создание, обновление или удаление сущностей в базе данных. Сам сервер, написанный под платформой .NET Core 3.0, получает информацию извне с помощью специальной конечной сетевой точки (англ. endpoint), подключиться к которой могут, к примеру, прокси-сервера или клиенты. После подключения две точки могут пересылать друг другу информацию, обычно это происходит с помощью специального протокола передачи структурированных данных, в котором описаны все возможные сообщения для передачи. С помощью такого протокола сериализации данных сервер сможет корректно интерпретировать переданную информацию от другого сервера или клиента, поскольку не всегда это удается сделать без протокола из-за передачи в бинарном виде. Такая архитектура позволяет эффективно обрабатывать и хранить большие объемы данных. Высокопроизводительный сервер предназначен для получения информации из многих источников, ее обработки и сохранения в базу данных. Асинхронная модель сервера позволит не только увеличить показатели производительности (пропускная способность, скорость ответа и др.), но и эффективное получение данных от многих клиентов одновременно.
Заключение
В рамках данного доклада была описана актуальная задача по проектированию и разработке высокопроизводительного сервиса для обработки больших объемов данных, проанализированы различные технологии и на их основе предложено решение и архитектура проекта.
