Статья:




АНАЛИЗ МЕТОДА ГЛУБОКОГО МУЛЬТИАГЕНТНОГО ОБУЧЕНИЯ НА ОСНОВЕ ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ
Секция: Технические науки
Выходные данные
Еремичев К.А. АНАЛИЗ МЕТОДА ГЛУБОКОГО МУЛЬТИАГЕНТНОГО ОБУЧЕНИЯ НА ОСНОВЕ ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ // Технические и математические науки. Студенческий научный форум: электр. сб. ст. по мат. LI междунар. студ. науч.-практ. конф. № 6(51). URL: https://nauchforum.ru/archive/SNF_tech/6(51).pdf (дата обращения: 30.07.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 0 голосов
Мне нравится0
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

LI Студенческая международная научно-практическая конференция «Технические и математические науки. Студенческий научный форум»
АНАЛИЗ МЕТОДА ГЛУБОКОГО МУЛЬТИАГЕНТНОГО ОБУЧЕНИЯ НА ОСНОВЕ ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ
Еремичев Константин Андреевич
студент, Московский государственный технический университет им. Н.Э. Баумана, РФ, г. Москва
Алфимцев Александр Николаевич
научный руководитель, д-р. техн. наук, профессор,
Московский государственный технический университет
им. Н.Э. Баумана,
РФ, г. Москва
Введение
В рамках данной статьи будет описан процесс исследования концепции обучения агента при помощи генеративно-состязательных нейронных сетей.
На фоне быстро протекающего процесса всеобъемлящей автоматизации и информатизации большое распространение получил особый тип информационных систем, называемых нейронными сетями. Огромные массивы данных, требующие быстрой обработки и анализа, а также отсутствие ярко-выраженных взаимосвязей между ними приводят к тому, что в некоторых ситуациях классические алгоритмы обработки данных терпят неудачу: к примеру, написание качественной программы для распознавания образов с использованием процедурного подхода является практически неподъемной задачей. С данной задачей намного лучше справляются нейронные сети.
В современном мире существует большое количество различных типов нейронных сетей, а также моделей их обучения, на которые в данной статье и будет сосредоточено основное внимание.
В рамках научного исследования был изучен сравнительно недавно описанный метод обучения генеративно-состязательных нейронных сетей [1]. Для проведения анализа работоспособности и качественной оценки работы данного метода обучения была разработана тестовая обучающая модель для нейронной сети, имитирующей поведение игрового агента в компьютерной игре Starcraft, разработанной компанией Blizzard.
1. Исследовательская часть
В данной части статьи будут введены основные концепции, термины и понятия, необходимые для лучшего понимания сути дальнейшей работы. Отдельные подразделы будут посвящены математическим моделям, используемым при моделировании состязательных и игровых процессов, моделям обучения агентов, а также генеративно-состязательным сетям
1.1 Математическая модель процесса принятия решений Маркова
Одним из традиционных подходов, описывающих взаимодействие отдельных агентов со стационарной окружающей средой, является модель процесса принятия решений Маркова. В силу своей простоты и понятности данная модель будет использована при моделировании агентов в данной статье. Далее будет приведено ее краткое описание.
Основные понятия, описывающие среду и взаимодействия агента с ней в модели принятия решений Маркова [2]:
- Состояния среды;
- Вероятностное распределение, характеризующее способность среды переходить из одного состояния в другое;
- Действия, которые может выполнять агент в различных состояниях среды;
- Политики (вероятностные распределения, характеризующие поведение агента в том или ином состоянии среды);
- Функция вознаграждения.
Функция вознаграждения является одним из важнейших понятий процесса принятия решений Маркова, ее основная цель состоит в поощрении определенного поведения агента и штрафах агента за несоответствующее поведение.
Процесс принятия решений в данной опирается на условие того, что в каждой, описываемой одноагентной системе существует политика, способная привести агента к максимальному вознаграждению, а целью каждого агента является нахождение данной оптимальной политики.
1.2 Основы обучения агентов
Одной из традиционных моделей, описывающих процесс выбора агентом наилучшей политики для максимизации получаемого вознаграждения, является модель обучения с подкреплением [3]. Основной задачей обучения с подкреплением является выбор политики, которая сделает действия агента наиболее выгодными в данной среде при данных правилах взаимодействия. Чем больше получаемое вознаграждение, тем выгоднее считается подобранная политика.
Для качественного обоснования выбора наиболее выгодной политики данная модель вводит следующие понятия:
- Value function (от англ. функция значения) V(s). Данная функция характеризует математическое ожидание вознаграждения, получаемого агентом за всю игру, в случае, если агент начнет ее из заданного состояния;
- Q function (кью функция) q(s,a). Данная функция характеризует математическое ожидание вознаграждения, получаемого агентом за всю игру, в случае, если агент начнет взаимодействие со средой из заданного состояния и произведет в нем заданное действие.
По данным функциям при помощи уравнения Белмана (1), есть возможность восстановить траекторию действий агента, приводящую к максимальному вознаграждению.
 (1)
(1)
Однако, у данной модели есть существенный недостаток, подбор функции вознаграждения, отвечающей всем требованиям и тонкостям описываемых процессов, в случае их сложности, может явиться крайне сложной проблемой, требующей больших затрат, а иногда и не имеющей решения при ограниченных временных вычислительных ресурсах. Возникает потребность в создании модели, которая сможет определить оптимальную политику для агента без доступа к объективной функции вознаграждения.
Данную возможность предоставляет модель, именуемая обратным обучением с подкреплением [4]. Целью данного подхода является обучение агента генерировать свою оптимальную политику взаимодействия со средой и другими агентами, основываясь не на доступе к функции вознаграждения, а на поведении, которое демонстрирует эксперт (эталонный агент). Наблюдая за распределениями вероятности совершения действий по различным состояниям среды, обучаемый агент, называемый генератором, определяет свою собственную политику, согласно которой будут выбраны его дальнейшие действия. Основной задачей данного типа обучения является максимальное приближение политики агента-генератора к политике эксперта, что неявно максимизирует получаемую агентом награду.
1.3 Введение в генеративно-состязательные сети
Модели, описанные в подразделе 1.2 могут быть неявно использованы для обучения агента, модель которого представляет собой нейронную сеть. На вход данной модели будут подаваться значения переменных среды, на выходах будут устанавливаться вероятности выбора того или иного действия при заданных состояниях среды. Таким образом задача обучения агента, не имеющего доступа к функции вознаграждения, по действиям эксперта превращается в задачу обучения нейронной сети для повторения поведения эталонного агента.
Одним из известных подходов для решение данной задачи на сегодняшний день является модель обучения генеративно-состязательных сетей. Основные составные элементы данной модели:
- Эталонная выборка данных, ее роль применимо к игровой модели может выполнять поведения эксперта в определенных условиях;
- Сеть-генератор, нейронная сеть, которая пытается сгенерировать данные таким образом, чтобы оппонент (дискриминатор) не заметил разницы между сгенерированной и эталонной выборками;
- Сеть-дискриминатор, нейронная сеть, которая пытается минимизировать ошибку при классификации данных на сгенерированные и эталонные.
Суть работы данного метода обучения схематично изображена на рисунке 1

Рисунок 1. Схема работы модели генеративно-состязательных сетей
Для наилучшего результата генератор и дискриминатор обучаются параллельно, для поддержания максимального уровня конкуренции меду ними.
2. Анализ существующей модели
В данной части статьи будет описана и проанализирована работа модели обучения нейронных сетей, выбранной для сравнения с изучаемой в статье моделью. Раздел включает в себя выбор модели обучения, описание данной модели, а также анализ ее работы.
2.1 Выбор существующей модели обучения
Для качественной оценки модели обучения с использованием генеративно-состязательных сетей, подберем еще одну обучающую модель, которая уже зарекомендовала себя как качественная и надежная. В данной статье была использована модель обучения нейронной сети, основанная на традиционном подходе обучения с подкреплением. Для наглядности в качестве агента будем использовать нейронную сеть, имитирующую поведение игрока в компьютерной игре Starcraft, разработанной компанией Blizzard. Для моделирования игровой среды была использована библиотека SMAC языка программирования Python, вся описываемая модель также целиком была реализована на данном языке с использованием фреймворка Pytorch.
2.2 Описание существующей модели
Модель агента представляет собой нейронную сеть, на вход которой передается набор переменных среды, в данной конфигурации агента было использовано 23 переменных, среди которых действия других агентов, описание свободного пространства и прочие необходимые для ориентации агента данные. Нейронная сеть имеет семь выходов, каждый из которых соответствует вероятности совершения одного из семи доступных действий в заданной входными переменными ситуации. Помимо входов и выходов нейронная сеть имеет два внутренний слоя из 60 и 66 нейронов.
Схематично данная сеть представлена на рисунке 2
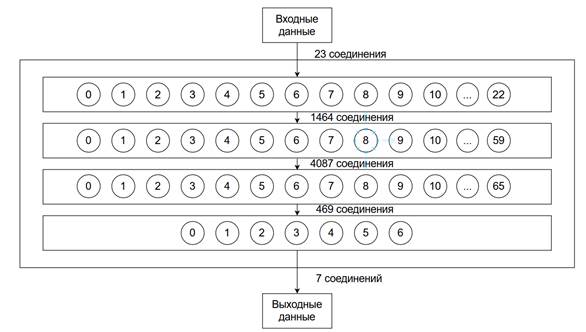
Рисунок 2. Схематичное изображение структурны нейронной сети
В процессе обучения проводится некоторое количество обучающих игр, в качестве минимизируемого параметра при оптимизации выступает ошибка между максимально возможной наградой за ход и полученной наградой. Положительные результаты и относительно адекватное поведение агентов можно наблюдать по прошествии 130-150 тренировочных игр.
2.3 Анализ работы существующей модели
В данном подразделе отражены результаты обучения и следующих за обучением тестовых игр.
Программа прошла обучение за 5,5 минут, разыграв 150 пробных игр.
Графики, характеризующие процесс обучения изображены на рисунках 3-5
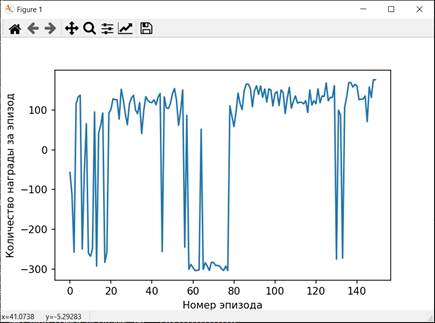
Рисунок 3. График наград, полученных за эпизоды при обучении
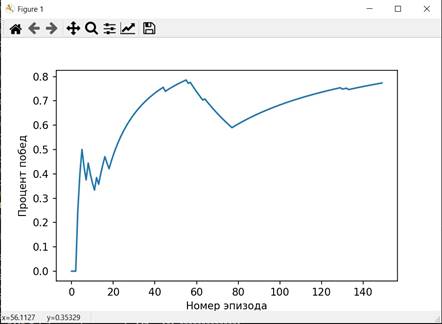
Рисунок 4. График распределения побед по эпизодам
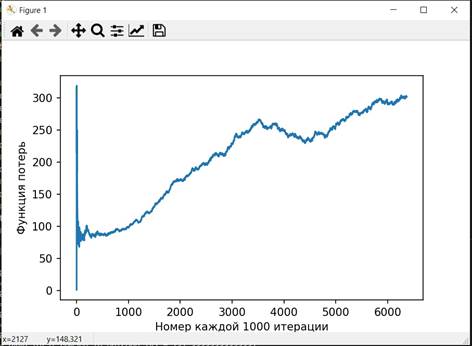
Рисунок 5. График изменения функции потерь при обучении, в зависимости от номера итерации
После обучения были проведены тестовые игры, статистика по ним изображена на рисунке 6.

Рисунок 6. Зависимость средней награды от номера игры
3. Анализ изучаемой модели обучения
В данной части статьи будет описана изучаемая модель обучения генеративно-состязательных сетей, а также будет произведено ее качественное сравнение с моделью из предыдущего части. Данный раздел включает в себя описание используемого метода обучения, описание разрабатываемой модели и анализ ее работоспособности.
3.1 Используемый метод обучения
В данной части для обучения игрового агента будет использована модель, являющаяся объектом изучения в данной статье, обучение с использованием генеративно-состязательных сетей. Для сравнения качества обучения агента по данной модели с моделью из предыдущего раздела будем использовать туже самую игровую среду и заранее сгенерированную карту.
3.2 Описание разрабатываемой модели
Как следует из описания используемой модели обучения, для тестирования нам понадобятся две нейронные сети: генератор и дискриминатор, а также выборка эталонных данных.
В качестве эталонной выборки были выбраны вероятности действий, выданные агентом, обучаемым в разделе 2, а также набор состояний среды, для которого были сгенерированы данные вероятности.
В качестве нейронной сети-генератора была выбрана сеть, имеющая 23 нейрона на входе (по числу переменных, описывающих состояния среды), 66 нейронов внутреннего слоя, а также 7 выходов, значения которых должны быть максимально близкими к значениям, которые для тех же состояний среды генерировал эталонный агент.
Структура неронной сети-генератора представлена на рисунке 7

Рисунок 7. Схематичное представление нейронной сети генератора
В качестве нейронной сети дискриминатора была выбрана сеть, имеющая 30 нейронов на входе (переменные, описывающие состояния среды и набор вероятностей, сгенерированный для них агентом), 66 нейронов внутреннего слоя, а также один выход, принимающий значения 0 или 1, в зависимости от того, кем по мнению дискриминатора была сгенерирована выборка, генератором или экспертом.
Структура нейронной сети-дискриминатора представлена на рисунке 8
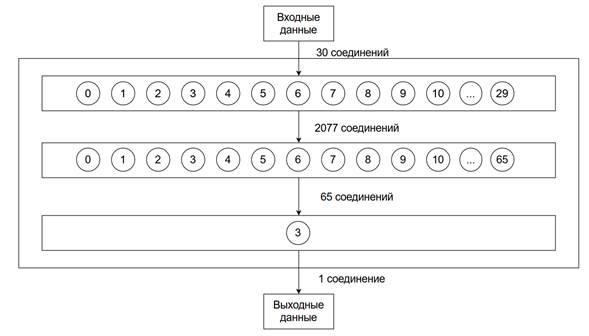
Рисунок 8. Схематичное изображение структуры нейронной сети дискриминатора
В процессе обучения наряду с выборками, производимыми экспертом на вход дискриминатору подаются выборки, производимые генератором. Перед дискриминатором ставится задача уменьшить ошибку, возникающую при классификации, задача классификатора увеличить ошибку дискриминатора.
Действия, похожие на действия эталонного агента можно заметить по прошествии 250-300 тренировочных игр. При более тщательном подборе скоростей обучения генератора и дискриминатора можно добиться лучших результатов, данные улучшения можно произвести в дальнейшем. Также при введении в алгоритм коэффициента похожести удалось сгенерировать поведение, не однозначно копирующее действия эксперта, а подстраивающееся под них с некоторыми изменениями.
3.3 Анализ работы разрабатываемой модели
В данном подразделе отражены результаты обучения и следующих за обучением тестовых игр.
Программа прошла обучение за 3,5 минут, разыграв 150 пробных игр.
Графики, характеризующие процесс обучения изображены на рисунках 9-10
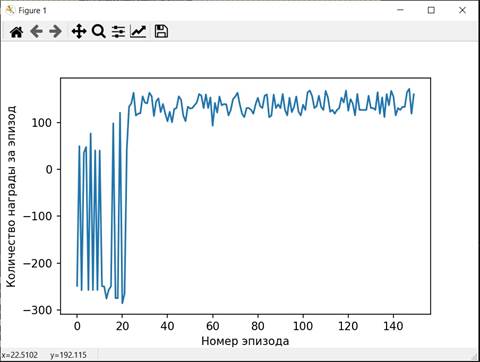
Рисунок 9. График наград, полученных за эпизоды при обучении
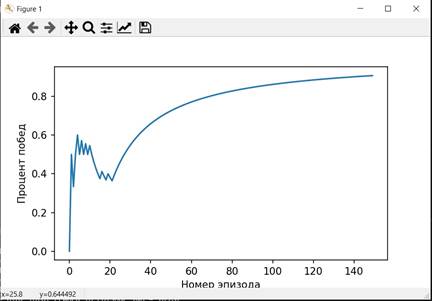
Рисунок 10. График распределения побед по эпизодам
После обучения были проведены тестовые игры, статистика по ним изображена на рисунке 11.

Рисунок 11. Зависимость средней награды от номера игры
Нейронная сеть, обученная по генеративно-состязательной модели показала результат не хуже сети, описанной в разделе 2 данной статьи, сеть, описанная в настоящем разделе имеет немного лучшую статистику средних наград при тестировании (возможно воздействие элемента случайность), стабильно лучшую статистику при обучении, кроме того на обучение затрачено в 1,5 раза меньше времени при том же числе обучающих игр, что свидетельствует о более быстрой работе данной модели.
Заключение
В данной научной статье было произведено изучение генеративно-состязательного метода обучения нейронных сетей, а также был проведен анализ работы простой тестовой модели обучения игрового агента. В процессе тестирования была подтверждена жизнеспособность и эффективность обучения агентов по данному методу. Сравнительный анализ, проведенный в разделе 3 свидетельствует о его качестве.
Для более ясных и определенных результатов необходимо продолжить изучение данного метода, построить и протестировать более сложные и эффективные модели для обучения. В ходе статьи были выделены два направления представляющих интерес: возможность более быстрого обучения агента по сравнению с другими методами за счет сокращения сложности обучаемой нейронной сети. Не требуется точный анализ исходной функции награды для обучения, следовательно, модель нейронной сети может быть упрощена, так как она должна анализировать лишь поведение агента эталона и некоторые наиболее влияющие на поведение входные параметры. Во-вторых, данный метод обучения можно использовать для того, чтобы формировать уникальные модели поведения для агентов на основе поведения нескольких эталонных агентов, объединяя тем самым их сильные стороны.
Список литературы:
1. Song, Jiaming, Hongyu Ren, Dorsa Sadigh, and Stefano Ermon. "Multi-agent generative adversarial imitation learning." In Advances in neural information processing systems, pp. 7461-7472. 2018.
2. M. L. Littman, “Markov games as a framework for multi-agent reinforcement learning,” in Proceedings of the eleventh international conference on machine learning, vol. 157, pp. 157– 163, 1994
3. R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction, vol. 1. MIT press Cambridge, 1998.
4. A. Y. Ng, S. J. Russell, et al., “Algorithms for inverse reinforcement learning.,” in Icml, pp. 663– 670, 2000.
