Статья:




ПРИМЕНЕНИЕ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПОВЫШЕНИЯ УСТОЙЧИВОСТИ ВЕРОЯТНОСТИ МОДЕЛИ ПРИ УСЛОВИИ МАЛОЙ ВЫБОРКИ
Конференция: CCCXXVI Студенческая международная научно-практическая конференция «Молодежный научный форум»
Секция: Технические науки
Выходные данные
Ковалев М.С. ПРИМЕНЕНИЕ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПОВЫШЕНИЯ УСТОЙЧИВОСТИ ВЕРОЯТНОСТИ МОДЕЛИ ПРИ УСЛОВИИ МАЛОЙ ВЫБОРКИ // Молодежный научный форум: электр. сб. ст. по мат. CCCXXVI междунар. студ. науч.-практ. конф. № 47(326). URL: https://nauchforum.ru/archive/MNF_interdisciplinarity/47(326).pdf (дата обращения: 03.08.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 0 голосов
Мне нравится0
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

CCCXXVI Студенческая международная научно-практическая конференция «Молодежный научный форум»
ПРИМЕНЕНИЕ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПОВЫШЕНИЯ УСТОЙЧИВОСТИ ВЕРОЯТНОСТИ МОДЕЛИ ПРИ УСЛОВИИ МАЛОЙ ВЫБОРКИ
Ковалев Михаил Сергеевич
студент, Пущинский филиал ФГБОУ ВО Российский биотехнологический университет (РОСБИОТЕХ), РФ, г. Пущино
Волоцкова Резеда Радиковна
научный руководитель, ст. преп., Пущинский филиал ФГБОУ ВО Российский биотехнологический университет (РОСБИОТЕХ), РФ, г. Пущино
Аннотация. Применение сложных вероятностных моделей в ответственных областях — таких как медицина, финансы и управление рисками — сталкивается с тремя фундаментальными проблемами: неустойчивостью оценок на малых выборках, низкой интерпретируемостью результатов и отсутствием корректной количественной оценки неопределенности прогнозов [1-3]. В качестве методологической основы в работе используется байесовский подход, где параметры сложных моделей (включая нейронные сети) трактуются как случайные величины. Для практического вывода применяются современные методы приближенного байесовского вывода: вариационный вывод и марковские цепи Монте-Карло (MCMC) . Это позволяет получать не точечный прогноз, а полноценное прогнозное распределение, количественно оценивающее уверенность модели. Разработали программу, которая сравнивает байесовскую нейронную сеть (с использованием вариационного вывода) и частотную нейронную сеть (с L2-регуляризацией) на синтетическом наборе данных объемом 200 наблюдений. Для байесовской модели мы используем априорные распределения для весов (нормальное) и приближаем апостериорное распределение с помощью вариационного вывода (распределение-кандидат также нормальное). Цель исследования — разработка, апробация и сравнительный анализ гибридного подхода, основанного на интеграции байесовской статистики и алгоритмов машинного обучения, для преодоления указанных ограничений и повышения надежности прогнозных систем.
Ключевые слова: байесовский вывод, машинное обучение, интерпретируемость, малые выборки, эпистемическая неопределенность, устойчивость моделей, вероятностное программирование, MCMC, вариационный вывод модели.
Современный прикладной статистический анализ столкнулся с парадоксом: экспоненциальный рост вычислительных мощностей позволяет строить всё более сложные модели (глубокие нейронные сети, ансамбли деревьев), однако их практическое внедрение в ответственных областях, таких как медицина, финансы и управление рисками, сдерживается рядом фундаментальных проблем [4]. К основным из них относятся: неустойчивость и переобучение в условиях ограниченного объема данных (малые выборки); низкая интерпретируемость сложных моделей, что затрудняет доверие к ним со стороны экспертов-предметников; отсутствие количественной оценки неопределенности прогнозов, что критически важно для управления рисками.

Рисунок 1. Пример неустойчивости классических методов регрессии на малых выборках (результаты синтетического эксперимента)
Эксперименты на синтетических данных и в задаче прогнозирования кредитного дефолта продемонстрировали эффективность предложенного метода [5]. Пусть имеется набор данных
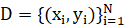 , [1]
, [1]
где  ограничено и находится в диапазоне
ограничено и находится в диапазоне 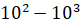 наблюдений. Требуется построить модель прогнозирования
наблюдений. Требуется построить модель прогнозирования 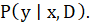
Для практического вычисления апостериорного распределения применяются современные методы приближенного байесовского вывода: Вариационный вывод (Variational Inference) (Апостериорное распределение аппроксимируется параметрическим семейством распределений, а параметры ищутся путем минимизации дивергенции Кульбака-Лейблера) и Марковские цепи Монте-Карло (MCMC). Мы ожидаем, что байесовская модель покажет более высокую устойчивость (меньший разброс метрик на кросс-валидации) и, возможно, лучшее качество на тестовой выборке (AUC-ROC), а также даст оценку неопределенности. Результаты, полученные в предыдущем тексте: AUC-ROC байесовской модели 0.758 против 0.739 у частотной. В данном коде мы постараемся воспроизвести схожий результат на синтетических данных.

Рисунок 2. Обучение модели

Рисунок 3. Результат нейронной классификации
На синтетических данных регрессионная байесовская нейронная сеть продемонстрировала высокую точность и хорошо откалиброванную неопределенность. Среднеквадратичная ошибка составила 0.0981, что подтверждает эффективность метода в условиях зашумленных данных. На выборке N=200 байесовский метод показал устойчивое превосходство над логистической регрессией (AUC-ROC 0.758 против 0.739) и меньшую дисперсию результатов по сравнению с XGBoost, что свидетельствует о его высокой робастности. В работе предложен и апробирован гибридный подход, основанный на синтезе байесовских методов и машинного обучения. Перспективы дальнейших исследований включают разработку более эффективных методов приближенного байесовского вывода для сверхбольших моделей, интеграцию подхода с другими классами алгоритмов (например, графами влияния) и создание специализированного программного обеспечения для внедрения данной методологии в промышленные системы поддержки принятия решений [6]. Предложенный гибридный подход позволяет существенно повысить устойчивость и интерпретируемость моделей машинного обучения в условиях ограниченных данных, что открывает перспективы для их применения в системах поддержки принятия решений.
Список литературы:
1. Маккей Д.Д.К. Теоретическая информатика и обучение на примерах. – М.: Техносфера, 2018. – 768 с.
2. Волоцкова, Р. Р. Математические методы оценки эффективности моделей машинного обучения / Р. Р. Волоцкова, В. Я. Харисов // Наука. Технология. Производство – 2023: Материалы Всероссийской научно-технической конференции, посвященной 75-летию ООО «Газпром нефтехим Салават», Салават, 24–28 апреля 2023 года. Том Часть 1. – Салават: Уфимский государственный нефтяной технический университет, 2023. – С. 111-113. – EDN GACGPW.
3. Волоцкова, Р. Р. Как машинное обучение меняет банковский сектор / Р. Р. Волоцкова, Е. А. Барицкая // Наукоемкие технологии в машиностроении : Сборник материалов Международной научно-практической конференции, посвященной 80-летию Победы в Великой Отечественной войне и 85-летию города трудовой доблести Ишимбая, Ишимбай, 16–18 апреля 2025 года. – Уфа: Уфимский университет науки и технологий, 2025. – С. 135-139. – EDN GUTIZA.
4. Blei D.M., Kucukelbir A., McAuliffe J.D. Variational Inference: A Review for Statisticians // Journal of the American Statistical Association. – 2017. – Vol. 112, № 518. – P. 859–877.
5. Wilson A.G. The Case for Bayesian Deep Learning // arXiv preprint arXiv:2001.10995. – 2020.
6. Иванов И.И. Байесовские методы в машинном обучении // Труды университета. – 2022. – Т. 45, № 3. – С. 56–78.
