Статья:




Идентификация голоса человека на основе мел-частотных кепстральных коэффициентов
Секция: Технические науки
Выходные данные
Иванов В.И., Тимофеев М.В. Идентификация голоса человека на основе мел-частотных кепстральных коэффициентов // Молодежный научный форум: Технические и математические науки: электр. сб. ст. по мат. XLV междунар. студ. науч.-практ. конф. № 5(45). URL: https://nauchforum.ru/archive/MNF_tech/5(45).pdf (дата обращения: 16.07.2026)
Лауреаты определены. Конференция завершена
Эта статья набрала 18 голосов
Мне нравится18
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

XLV Студенческая международная заочная научно-практическая конференция «Молодежный научный форум: технические и математические науки»
Идентификация голоса человека на основе мел-частотных кепстральных коэффициентов
Иванов Вячеслав Игоревич
студент, Морской Государственный Университет им. адм. Г.И. Невельского, РФ, г. Владивосток
Тимофеев Михаил Вячеславович
студент, Морской Государственный Университет им. адм. Г.И. Невельского, РФ, г. Владивосток
Гончаров Сергей Михайлович
научный руководитель, канд. физ.-мат. наук, доц., Морской Государственный Университет им. адм. Г.И. Невельского, РФ, г. Владивосток
Технологии и средства идентификации по голосу применяются в ряде областей, непосредственно связанных с обработкой обращений пользователей по телефону, что позволяет ускорить обслуживание абонентов и разгрузить операторов, распознавание по голосу очень удобно для пользователей и требует от них минимум усилий.
Речь представляет собой акустическую волну, которая излучается системой органов: легкими, бронхами и трахеей, а затем преобразуется в голосовом тракте. Если предположить, что источники возбуждения и форма голосового тракта относительно независимы, речевой аппарат человека можно представить в виде совокупности генераторов тоновых сигналов и шумов, а также фильтров.
Мел-частотные кепстральные коэффициенты (Mel-frequency cepstral coefficients) или MFCC – это своеобразное представление энергии спектра сигнала.
Преимущество его использования заключаются в следующем:
· используется спектр сигнала, что позволяет учитывать волновую «природу» сигнала при дальнейшем анализе;
· спектр проецируется на специальную mel-шкалу, позволяя выделить наиболее значимые для восприятия человеком частоты.
На данный момент существует несколько распространённых способов распознавания речи.
Dynamic Time Warping (алгоритм динамической трансформации шкалы времени) – алгоритм, позволяющий найти наибольшее соответствие между последовательностями времени. С помощью него определяется то, как одну и ту же исходную произнесённую фразу представляют два речевых сигнала.
Недостаток алгоритма - он может выдавать неправильные результаты. Алгоритм может попытаться объяснить непостоянство оси 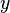 с помощью трансформации оси
с помощью трансформации оси 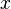 . Это может привести к выравниванию, из-за которого большая подгруппа точек второй последовательности ставится в соответствие одной точке первой последовательности.
. Это может привести к выравниванию, из-за которого большая подгруппа точек второй последовательности ставится в соответствие одной точке первой последовательности.
Hidden Markov Model (скрытая Марковская модель) – статистическая модель, имитирующая процесс, похожий на Марковский процесс с неизвестными параметрами, и задачей ставится вычисление неизвестных параметров на основе наблюдаемых. Эти параметры используют в дальнейшем анализе, например, для определения образов.
Недостатком Марковской модели является то, что состояния модели являются наблюдаемыми. Это либо ведет к неоправданному увеличения числа состояний, либо вообще становится невозможно описывать реальные лингвистические явления.
Support Vector Machine (метод опорных векторов) – перевод изначальных векторов в более высокую размерность и розыск разделяющей гиперплоскости с максимальным зазором в этом пространстве. Две параллельных гиперплоскости рисуются на обеих сторонах гиперплоскости, отделяющей наши классы. Отделяющей гиперплоскостью будет гиперплоскость, максимизирующая расстояние до двух параллельных гиперплоскостей. Алгоритм работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора.
Недостатком здесь - проблема подбора ядра, а также небыстрое обучение в случае задачи распознавания многих классах.
Gaussian Mixture Model (модель гауссовых смесей) –представляет собой взвешенную Гауссианскую сумму, широко используется в распознавания дикторов.
Часто в системах, использующих эту модель, используется диагональная матрица ковариации. Также возможно использование одной матрицы ковариации для всех компонентов модели диктора или одной матрицы для всех моделей.
Недостаток использования модели смесей Гаусса – трудность извлечения вектора признаков из каждого кадра, а еще в самом анализе выходных данных, так как трудно разделить их на классы.
Из-за трудности реализации и огромного количества операций вычисления использовать гауссовы смеси в задаче распознавания голоса ресурсозатратно, а из-за неоднозначности выходных данных сложно избавиться от ошибок.
Minimum-Distance Classification (минимальный промежуток классификации). Понятие минимального промежутка классификации простое. Как набор данных признаков используется MFCC и как меры промежутка мы используем средний квадрат разности между тестированными и обученными векторами.
Мы высчитываем вектор характеристик для каждого следующего проверяемого файла, и измеряем, насколько далеко он от данных обучения с помощью некой метрики для дистанционного вычисления. Затем мы подбираем пороговое расстояние для того, чтобы определить, когда идентификация речи успешна. Это расстояние будет определяться между числом ложных неправильных и ложных правильных срабатываний. Этот метод использовался в наших экспериментах, так как он наиболее удобен в реализации [1, c.40–41].
Алгоритм проведения эксперимента:
Обработка данных проводилась с использованием среды программирования MATLAB.
Этап 1. Преобразование из сигнала аналогового в цифровой. Частота дискретизации выбрана 8000 Гц делается 8000 измерений в секунду. На каждое значение амплитуды выделяется 16 бит. Сигнал, который мы оцифровали со скоростью потока 128 Кб/с в дальнейшем будем обозначать x[t].
Этап 2. Чтобы очистить от шума применим предварительную обработку сигналов. Функция Matlab – «wdencmp» использовалась для обработки. Затем использовалось высокочастотное усиление для того, чтобы компенсировать ослабление, которое вызванно рассеиванием от губ. Для этого блоки сигнала пропускались через фильтр первого порядка.
Этап 3. Извлечение спектральной информации для нашего уже обработанного сигнала, полученного на предыдущих этапах. На данном этапе необходимо выяснить, какое количество энергии содержится в каждом частотном диапазоне. Для извлечения спектральной информации применяется дискретное преобразование Фурье. На вход подается разбитый на фреймы(кусочки) сигнал, а на выходе для каждого из T частотных диапазонов – комплексное число X[K], представляющее собой амплитуду и фазу исходного сигнала:
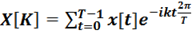 [2, с. 193]
[2, с. 193]
Затем осуществляется переход от величины частоты звука к значению высоты (мел) по формуле:
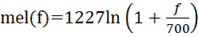
Простым перемножением векторов спектра сигнала и мел функции найдем энергию сигнала. Мы получили некоторый набор коэффициентов, но это еще не те MFCC, которые мы ищем. Возводим их в квадрат и логарифмируем. Чтобы получить из них кепстральные, мы еще раз применяем преобразование Фурье.
В результате мы получили набор мел-частотных кепстральных коэффициентов (MFCC).
Этап 4. Сравнение данных наборов MFCC.
Для сравнения использовался алгоритм «Minimum-Distance Classification»
В эксперименте участвовало 10 человек (8 парней и 2 девушки).
Каждый из них записывал по две фразы примерно одинаковой длины:
· «ни одно доброе дело не остается безнаказанным»;
· «русский мужик долго запрягает, да быстро скачет».
Первая фраза использовалась для обучения. Вторая фраза использовалась для тестирования. В результате сравнения мы получили таблицу 10х10. То есть всего было произведено 100 сравнений.
Таблица 1.
Результаты идентификации
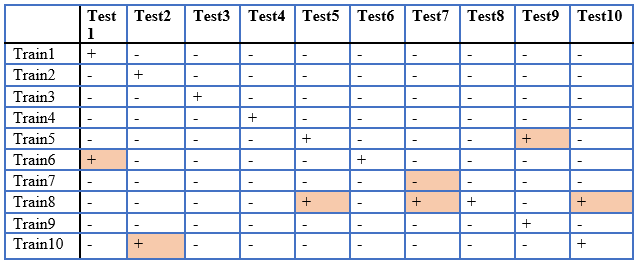
В таблице выделены ложные распознавания. Ошибка 2-го рода составляет 7%.
Выводы.
1. Проведены базовые эксперименты идентификация голоса диктора на основе мел-частотных кепстральных коэффициентов с использованием MATLAB.
2. Ошибка 2-го рода распознавания диктора составляет 7%.
3. Для повышения качества необходимо проведение дальнейших исследований с более сложной моделью обработки полученных данных.
Список литературы:
1. Запрягаев С. А., Коновалов А. Ю. Распознавание речевых сигналов // Вестник ВГУ, № 2, 2009, С. 39–48.
2. Ganchev T., Fakotakis N., Kokkinakis G. Comparative evaluation of various MFCC implementations on the speaker verification task // 10th International Conference on Speech and Computer. –– Patras, Greece, 2005, С. 191–194.
